
 Gdy włączamy PowerPivot po raz pierwszy, automatycznie jesteśmy w trybie zaawansowanym – oznacza to, iż mamy do swej dyspozycji zakładkę Zaawansowane, w której znajduje się kilka interesujących funkcji.
Gdy włączamy PowerPivot po raz pierwszy, automatycznie jesteśmy w trybie zaawansowanym – oznacza to, iż mamy do swej dyspozycji zakładkę Zaawansowane, w której znajduje się kilka interesujących funkcji.
Jeżeli jednak nie jesteśmy zainteresowani tą zakładką, zawadza nam podczas wykonywania naszej pracy, bądź też boimy się, że osoba która będzie korzystać z przygotowanego przez nas modelu popsuje coś przy pomocy znajdujących się tam funkcji, możemy przejść do trybu normalnego. W tym celu klikamy na ikonę menu znajdującą się na lewo od zakładki Narzędzia główne, a następnie wybieramy opcję Przełącz do trybu normalnego:
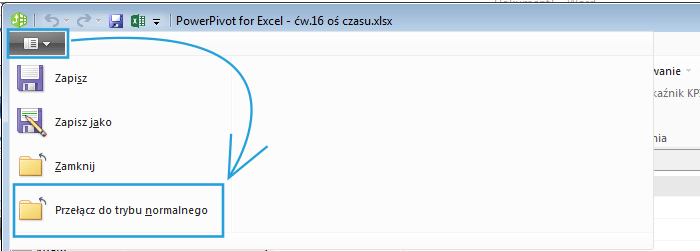
W ten sam sposób możemy też przełączyć się z powrotem do trybu zaawansowanego.
W interesującej nas zakładce znajdziemy przyciski dotyczące perspektywy: Utwórz i zarządzaj oraz Wybierz, przyciski Pokaż niejawne pola obliczeniowe, Sumuj według, oraz dwa przyciski bezpośrednio wpływające na PowerView oraz tabele przestawne: Domyślny zestaw pól i Zachowanie tabeli.

W tym artykule omówione zostaną poszczególne grupy funkcji.
1. Perspektywa.
Jest to narzędzie przydatne w przypadkach, gdy z jednego modelu danych korzysta wielu użytkowników o zróżnicowanych oczekiwaniach co do jego zawartości.
Narzędzie te pozwala na wyświetlanie określonego zestawu tabel oraz kolumn jaki jest potrzeby danemu użytkownikowi w danym momencie, oraz na szybką zmianę tego zestawu na inny.
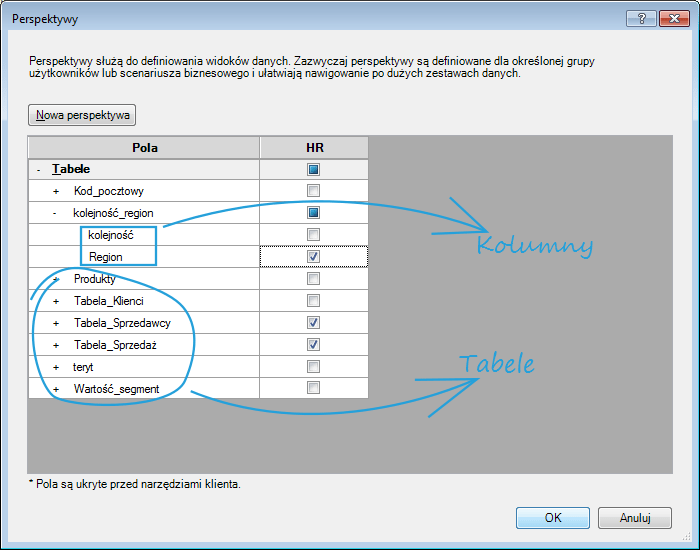
Przykładowo: W jednym modelu danych mogą znajdować się informacje na temat sprzedawców, ich skuteczności, najchętniej kupowanych produktów oraz ich ceny. Dział zajmujący się zasobami ludzkimi – HR – interesuje tylko skuteczność poszczególnych sprzedawców, więc perspektywa dla nich przygotowana będzie zawierała jedynie dane dotyczące poszczególnych sprzedawców i ich skuteczności. Dział zaopatrzeniowy będzie natomiast zainteresowany informacją które produkty najlepiej się sprzedają, i te dane będzie zawierała ich perspektywa.
Po stworzeniu relacyjnego modelu danych perspektywa, którą widzimy, zwie się domyślną – widoczne są po prostu wszystkie tabele oraz kolumny modelu danych.
Widok taki sprawdza się w przypadku, gdy mamy stosunkowo nieskomplikowany model, niewymagający ograniczenia ilości wyświetlanych tabel.
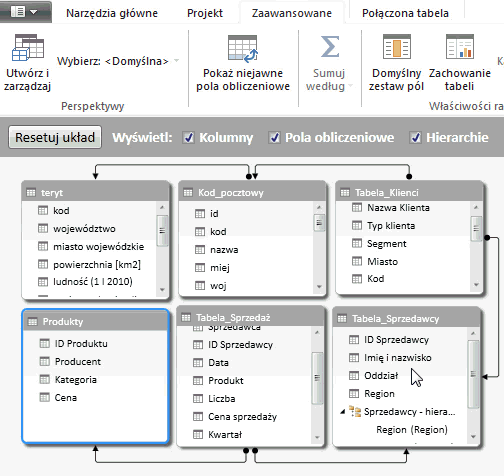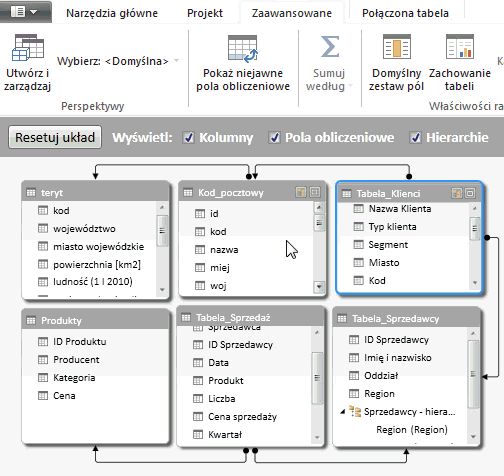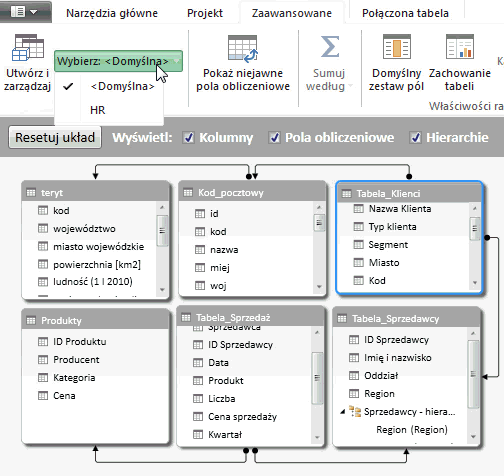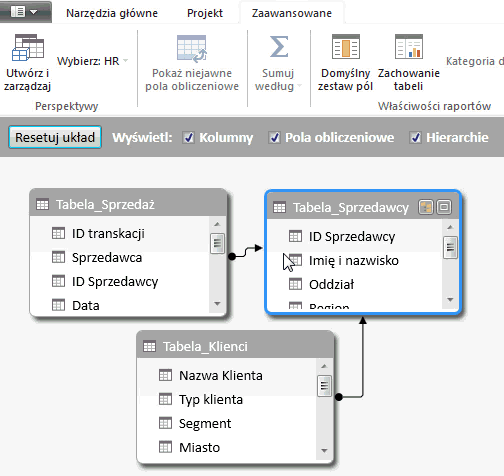
W celu utworzenia własnej perspektywy klikamy przycisk Utwórz i zarządzaj. Otworzy się okno Perspektywy. W nim to, po kliknięciu przycisku Nowa perspektywa możemy nadać jej nazwę, a następnie w prosty sposób sporządzić interesujący nas widok – wystarczy zaznaczyć odpowiednie pola obok interesujących nas tabel oraz poszczególnych kolumn. Obok nazw tabel są symbole plusów, po których kliknięciu rozwija się lista kolumn należących do tej tabeli.
Po najechaniu kursorem na kolumnę oznaczającą daną perspektywę nad jej nazwą pojawiają się 3 przyciski, które umożliwiają kolejno: usunięcie danej perspektywy, zmianę jej nazwy oraz skopiowanie jej w celu stworzenia nowej perspektywy na podstawie już istniejącej.

Jeżeli w utworzonej perspektywie będą znajdować się tabele połączone relacją, to relacja ta będzie dalej widoczna w widoku diagramu w PowerPivot.
Uwaga: Pomiędzy widokiem diagramu a widokiem danych w PowerPivot przełącza się przy pomocy przycisków znajdujących się w obszarze Widok zakładki Narzędzia główne:
Ograniczenie ilości tabel oraz kolumn skutkują znacznym zwiększeniem przejrzystości naszych danych:
2. Przycisk „Pokaż niejawne pole obliczeniowe”
Z definicją niejawnego oraz jawnego pola obliczeniowego (zwanego też zamiennie miarą) oraz konkretnymi przykładami można zapoznać się w tym artykule.
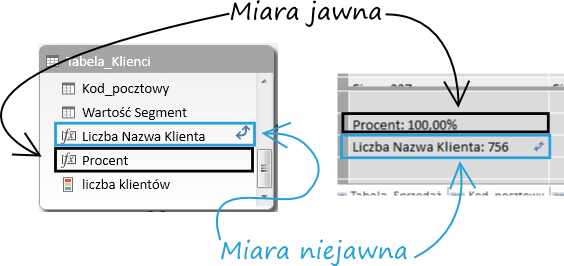
Stworzone niejawne miary domyślnie nie są widoczne w PowerPivot. Dopiero włączenie tej opcji (wciśnięty przycisk Pokaż niejawne pola obliczeniowe) powoduje, iż w obszarze obliczeń w widoku danych oraz w widoku diagramu pojawiają się niejawne pola obliczeniowe, które są oznaczone charakterystycznymi niebieskimi strzałkami:
Ważną kwestią jest to, iż można zobaczyć przy pomocy jakich funkcji zostały obliczone miary niejawne. Wystarczy kliknąć na takie pole w obszarze obliczeń w widoku danych PowerPivot i zerknąć na pasek formuły:
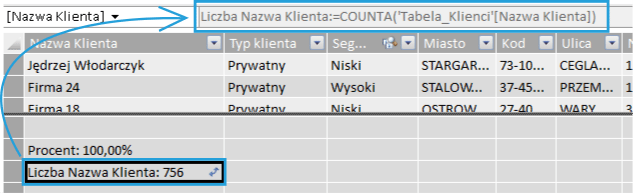
Nie można zmienić składni niejawnego pola obliczeniowego, o czym świadczy szary kolor czcionki.
Funkcja ta istotne jest to szczególnie dla początkujących użytkowników, którzy wzorując się na składni pól niejawnych mogą zacząć tworzyć własne miary jawne.
3. Przycisk „Sumuj według”
Kolejna funkcja również powiązania z tworzeniem niejawnych pól obliczeniowych.
Niejawne miary możemy tworzyć w oparciu o podstawowe funkcje języka DAX: Sumowanie, Liczność (wszystkich wierszy lub unikatowych wartości w tych wierszach), średnia, minimum oraz maksimum. Gdy nie chcemy tworzyć miary, wybieramy opcję „nie sumuj”, a PowerView lub też tabela przestawna będzie traktowała tą kolumnę jako zestaw indywidualnych wierszy, a nie liczby na których mają zostać wykonane jakieś działania.
Podczas tworzenia miary niejawnej (w tabeli przestawnej: poprzez przesuwanie kolumny do obszaru Wartości, w raporcie PowerView – poprzez przesuwanie kolumny oznaczonej symbolem „Σ” do obszaru POLA) domyślnie jest używana funkcja sumowania. Można oczywiście ręcznie zmieniać za każdym razem sposób obliczania miary.
Jednakże, jeżeli jakaś miara niejawna, nie będąca sumowaniem, będzie często używana, możemy sobie znacznie ułatwić pracę zmieniając domyślny typ danej kolumny na dowolny inny sposób agregacji miary niejawnej poprzez przycisk „Sumuj według”
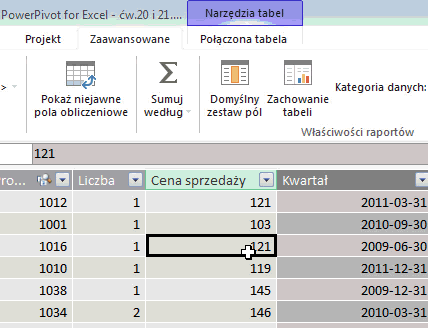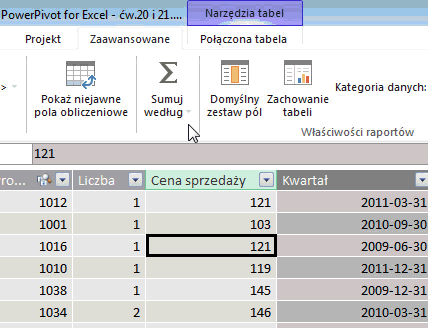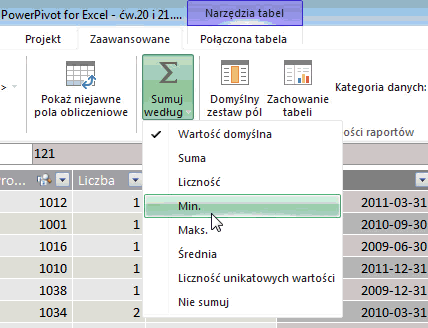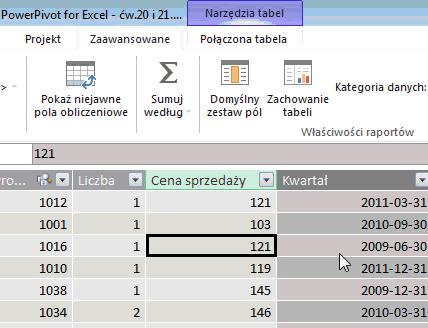
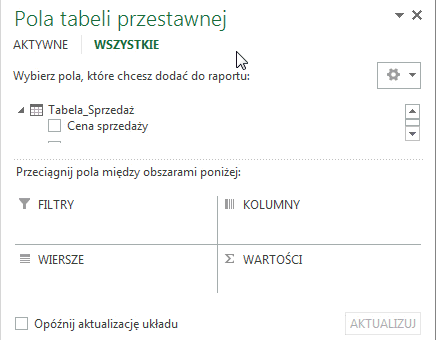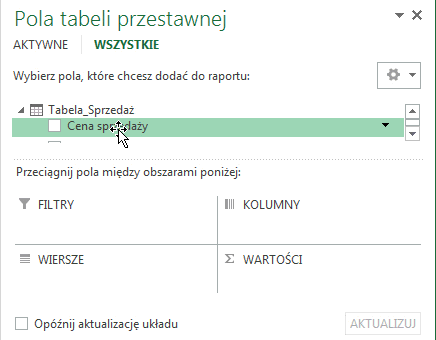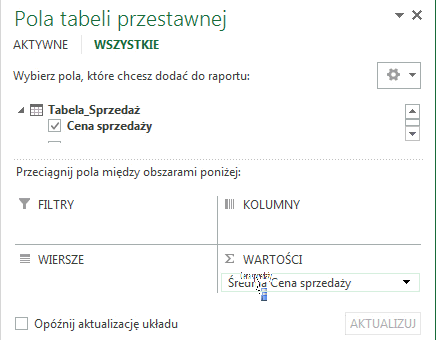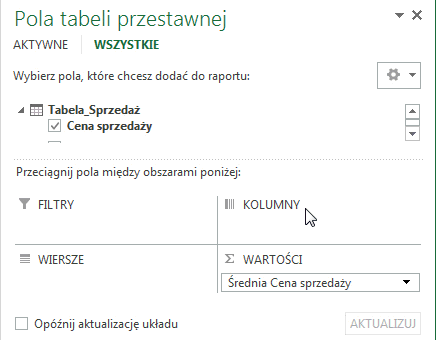
Dokonuje się tego w bardzo prosty sposób. W widoku danych w oknie PowerPivot klikamy na dowolną komórkę w interesującej nas kolumnie, której domyślny sposób chcemy zmienić. Następnie wybieramy przycisk „Sumuj według” i wybieramy interesującą nas funkcję – na przykład średnią:
W podobny sposób działa to w widoku diagramu PowerPivot – wystarczy zaznaczyć nazwę odpowiedniej kolumny i kliknąć Sumuj według:
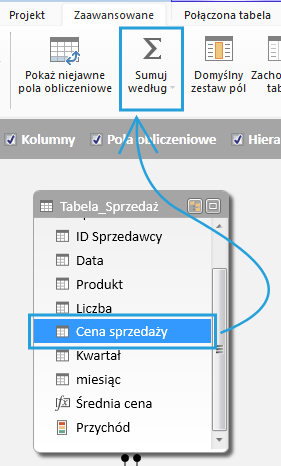
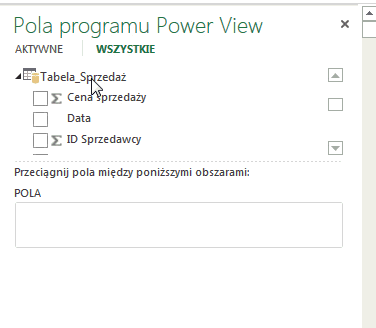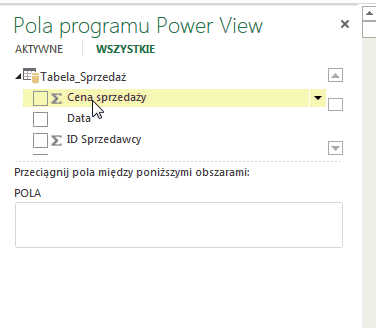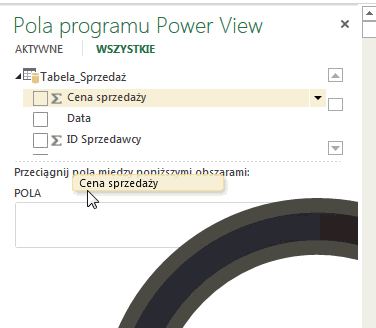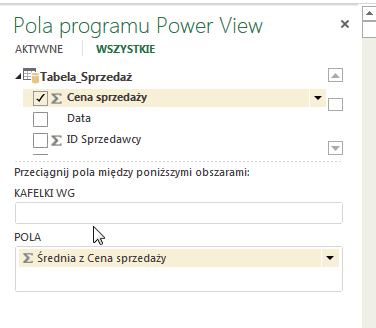
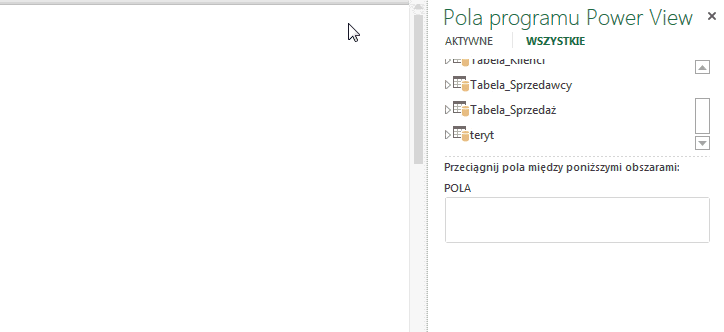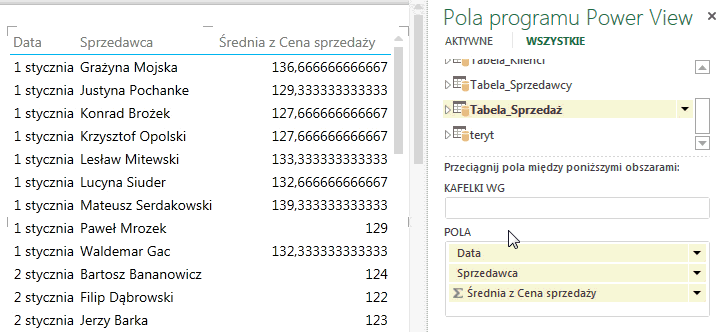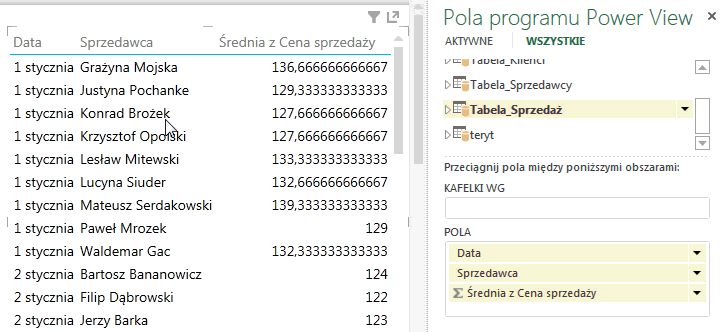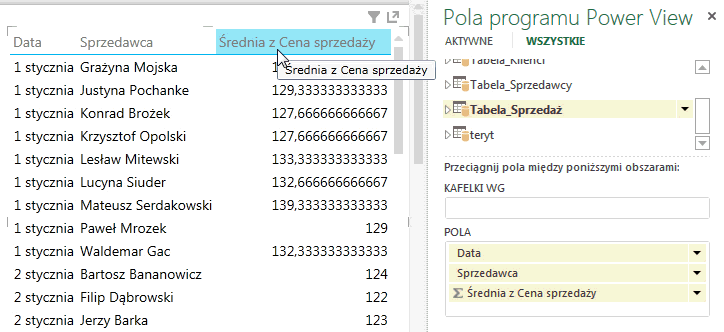
Od tej pory agregacja zarówno w tabeli przestawnej, jak i w PowerView w pierwszej kolejności będzie zachodziła agregacja według średniej:
4. Przycisk „domyślny zestaw pól”
Przy pomocy przycisku „Domyślny zestaw pól” możemy zdefiniować listę kolumn, która będzie dodawana do tabeli w raporcie PowerView już po kliknięciu nazwy tabeli – bez potrzeby wykonywania dodatkowych operacji. Pozawala to zaoszczędzić czas przy intensywnym wykorzystaniu określonego zestawu kolumn w danej tabeli.
W pierwszym kroku należy wybrać interesującą nas tabelę w PowerPivot – w widoku diagramu wystarczy kliknąć na odpowiednią ramkę, w widoku danych należy wybrać właściwą zakładkę. Następnie klikamy przycisk Domyślny zestaw pól, gdzie wybieramy (w kolejności) interesujące nas, często używane kolumny:
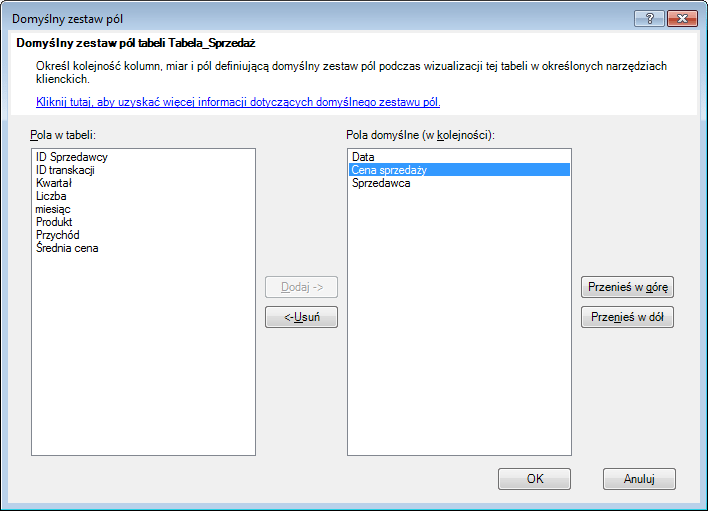
Kolumny przemieszczamy pomiędzy obydwoma obszarami przy pomocy przycisków Dodaj -> oraz <- Usuń. Kolejnością sterujemy przy pomocy przycisków Przenieś w górę i Przenieś w dół.
Po ustaleniu pól domyślnych oraz ich kolejności możemy przejść do raportu PowerView. Wystarczy kliknąć na nazwę tabeli w której zdefiniowaliśmy domyślny zestaw kolumn, aby pojawiła się tabela składająca się z tego właśnie zestawu.
Jeżeli zaznaczymy istniejącą już tabelę w raporcie i klikniemy na nazwę tabeli ze zdefiniowanym zestawem domyślnym pól, kolumny te dołączą się do zaznaczonej tabeli.
W przypadku kliknięcia na nazwę tabeli, która nie ma zdefiniowanego domyślnego zestawu pól, program nie wykona żadnej operacji.
5. Zachowanie tabeli
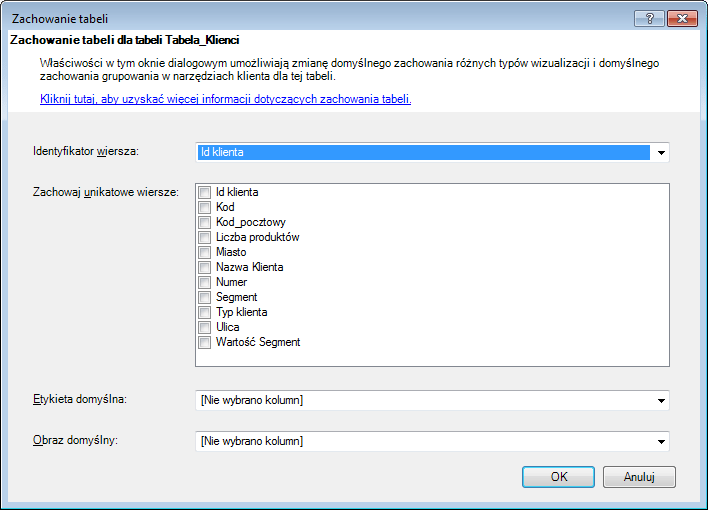
Po kliknięciu w przycisk Zachowanie tabeli otworzy nam się okno, w którym możemy określić identyfikator wiersza, zachować unikatowe wiersze, domyślną etykietę oraz obraz:
Co oznaczają poszczególne opcje?
Identyfikator wiersza określa kolumnę, w której znajdują się unikatowe wartości oraz nie zawiera pustych komórek. Dzięki temu każdy wiersz jest jednoznacznie identyfikowalny poprzez określoną wartość znajdującą się w kolumnie będącej identyfikatorem.
Istnienie oraz ustalenie takiej kolumny pozwala na skorzystanie z pozostałych opcji okna zachowanie tabeli.
Nazwa opcji zachowaj unikatowe wiersze jest nieco mylna – przy jej pomocy nie pozbywamy się powtórzeń określonych wartości w kolumnie, jakby można tego się spodziewać.
Funkcja ta odnosi się do przypadku, w którym, pomimo iż w danej kolumnie występują dwie identyczne wartości, nie należy ich zliczać razem. Sytuacja taka może wystąpić np. w przypadku bazy danych zawierających dane klientów – dwóch z nich może nazywać się tak samo. Inne dane, pozwalające ich rozróżnić – np. data urodzenia – mogą nie być wykorzystywane do tworzeia raportu. W takim przypadku program pokaże w raporcie tylko jednego takiego klienta, a wszystkie inne wykorzystywane w raporcie wartości będą sumą z obu tych wierszy.
Dzięki zastosowaniu opcji zachowaj unikatowe wiersze te dwa wiersze, w których będą występowali klienci o takich samych nazwiskach, nie zostaną zsumowane, lecz zostaną ukazane w raporcie oddzielnie, jako dwóch klientów o tych samych nazwiskach – tak jak jest to w rzeczywistości.
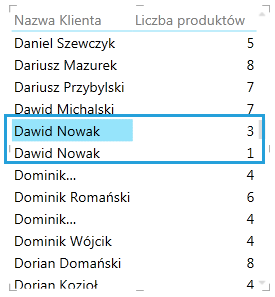
Przykład: W bazie danych istnieje dwóch klientów o nazwisku Dawid Nowak, nie jest to jednak jedna i ta sama osoba:

W domyślnym przypadku zostaną oni przedstawieni w raporcie jako jedna i ta sama osoba:

Wybranie kolumny Nazwa klienta w oknie Zachowaj unikalne kolumny spowoduje, iż tabela wyświetlana jest poprawnie – wyświetlają się dwa nazwiska Dawid Nowak, dotyczące dwóch różnych osób.
Pole Etykieta domyślna określa kolumnę, której zawartość będzie wyświetlana w tabeli typu karta jako główny napis, bądź też na jej podstawie powstanie oś wykresu lub podział wg kafelków.
Przykład:
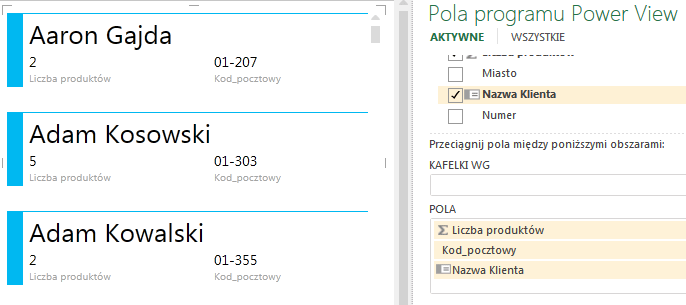
W przypadku niezdefiniowania domyślnej etykiety, o kolejności wyświetlania napisów w karcie decyduje kolejność umieszczenia kolumn w obszarze POLA. Ponieważ jednak kolumna Nazwa Klienta została zdefiniowana jako taka właśnie etykieta, zajmuje ona najważniejsze – pierwsze – miejsce w tej tabeli. Ponadto tekst etykiety jest napisany większą czcionką w porównaniu do pozostałych danych zamieszczonych w karcie.
Uwaga: Powyższa zależność odnosi się tylko do tabeli typu karta. W pozostałych przypadkach o kolejności wyświetlania decyduje kolejność w obszarze POLA.
Dodatkowo zdefiniowana etykieta domyślna będzie się wyświetlać pod obrazkami określonymi jako kafelki:
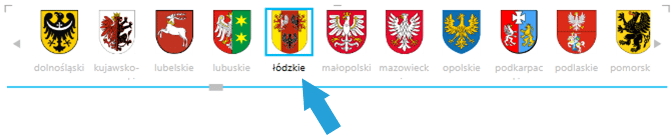
Efekt ten jest widoczny tylko wtedy, gdy Typ kafelka jest określony jako pasek kart:
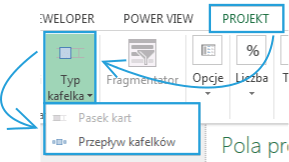
Jeżeli zmienimy typ na Przepływ kafelków etykiety nie będą widoczne pod obrazkami:

Pole Obraz domyślny działa w podobny sposób, co etykieta domyślna; dotyczy jednak obrazów. Obrazy można wyświetlać m.in. poprzez wskazanie odpowiedniego adresu URL.
Pole te określa obraz domyślnie wyświetlany w kafelkach oraz, podobnie jak w przypadku etykiety domyślnej, definiuje miejsce obrazu w tabeli typu karta. W przypadku znalezienia się w jednej karcie razem z etykietą domyślną, obraz ląduje pod tą właśnie etykietą.
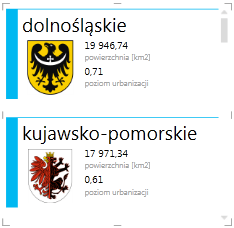
Jak łatwo zauważyć, definiowanie zachowania tabeli nie jest koniecznością. Problem z występowaniem tych samych nazwisk można rozwiązać też w inny sposób – wybierając w tworzącym się niejawnym polu obliczeniowym opcję „nie sumuj”, dzięki czemu dwa wiersze – nawet jeżeli będą miały identyczną wartość w polu identyfikującym – będą wyświetlane oddzielnie. Zamiast stosować etykietę i obraz domyślny, można po prostu je dodawać w odpowiedniej kolejności w obszarze POLA. Zdefiniowanie zachowania tabeli przydatne jest szczególnie w przypadkach dużych baz danych, na podstawie których wiele różnych osób, o różnym stopniu świadomości sposobu działania programu, będzie tworzyło raporty. Wtedy to już zawczasu można zadbać o to, aby nie było mowy o błędach w raportach wynikających ze zbieżności nazwisk, czy też nielogicznego rozmieszczenia etykiet oraz obrazów.
Jeżeli macie inną opinię – podzielcie się nią w komentarzach!


