


 Jedną z podstawowych funkcjonalności baz danych jest możliwość łączenia dwóch lub więcej tabel w jedną większą tabelę. W bazach danych obsługiwanych przy pomocy języka SQL istnieją odpowiednie komendy odpowiedzialne za te działania typu JOIN. Odpowiednie opcje przewidziano także w dodatku Power Query, które z powodzeniem mogą zastąpić Excelową formułę WYSZUKAJ.PIONOWO.
Jedną z podstawowych funkcjonalności baz danych jest możliwość łączenia dwóch lub więcej tabel w jedną większą tabelę. W bazach danych obsługiwanych przy pomocy języka SQL istnieją odpowiednie komendy odpowiedzialne za te działania typu JOIN. Odpowiednie opcje przewidziano także w dodatku Power Query, które z powodzeniem mogą zastąpić Excelową formułę WYSZUKAJ.PIONOWO.
Scalanie w Power Query
Zanim przejdziemy do omawiania PowerQuery, warto przypomnieć o odpowiedniku komendy JOIN obecnej w skoroszycie Excela, jaką jest funkcja WYSZUKAJ.PIONOWO . Warto jednak pamiętać, iż przy bardzo dużej liczbie rekordów w tabelach mogą pojawić się problemy z wydajnością.
Opcja Scal – podobnie jak komenda join w języku zapytań SQL – służy przyporządkowaniu rekordom z jednej tabeli odpowiednich rekordów z innej tabeli. W efekcie ich działania otrzymujemy tabelę która zawiera kolumny z obu tabel składowych. Aby takie działanie zaszło, w tabelach muszą znajdować się kolumny pełniąca funkcję Klucza głównego oraz Klucza obcego – inaczej rzecz mówiąc, w obu tabelach musi znajdować się kolumna zawierająca wartości na podstawie których możemy je powiązać.
Najłatwiej działanie tej opcji wytłumaczyć na przykładzie.
Załóżmy, iż mamy do dyspozycji tabele zawierające dane na temat klientów i obsługujących ich sprzedawców, a kolumna umożliwiającą powiązanie obu tabel zawiera ID sprzedawcy.
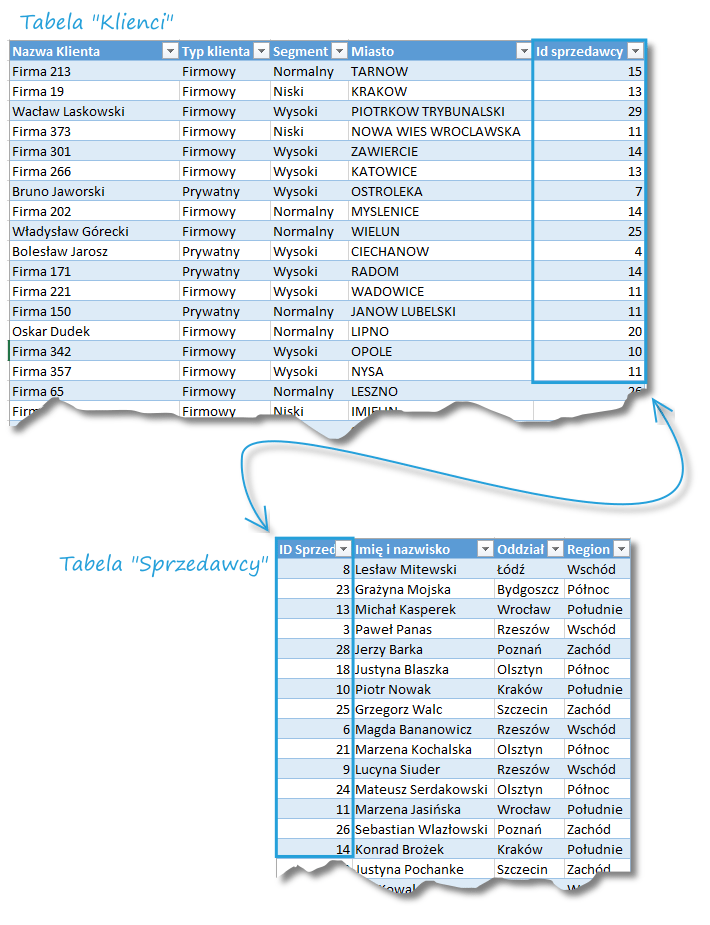
Na tej podstawie możemy stworzyć tabelę w której do każdego klienta będzie przypisany sprzedawca – z imienia, nazwiska, oddziału i regionu. Jednym ze sposobów jest wykorzystanie dodatku PowerQuery i opcji Scal.
Aby to zrobić, w pierwszej kolejności musimy załadować tabele do edytora zapytań – o sposobach importu tabel pisaliśmy w poprzedniej części.
Gdy już załadowaliśmy tabele do naszego pliku to z zakładki POWERQUERY wybieramy funkcję Scal:
Tą samą opcję znajdziemy także w Edytorze zapytań:

Otworzy się nam okno Scalanie, w którym wybieramy tabele które mają zostać połączone oraz zaznaczamy kolumny w których znajdują się klucz główny i klucz obcy:
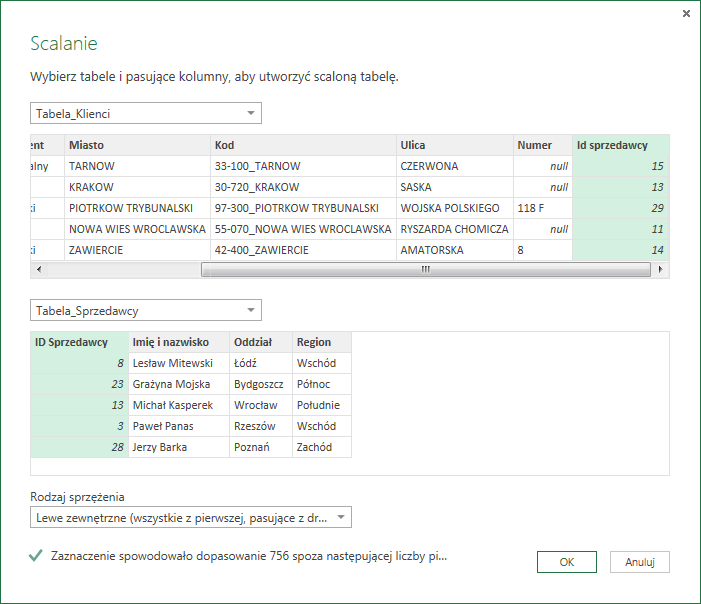
Od kolejności wybranych tabel oraz wybranego rodzaju sprzężenia zależy efekt końcowy, który może się diametralnie od siebie różnić. Do wyboru mamy następujące sprzężenia:

Każda powyższa opcja odpowiada pewnej wariacji komendy JOIN w języku SQL.
– Lewe zewnętrzne (wszystkie z prawej, pasujące z drugiej) jest odpowiednikiem komendy LEFT OUTER JOIN. Oznacza to, iż w tabeli wynikowej znajdą się wszystkie wiersze z tabeli pierwszej („lewej”) i te, które możemy przyporządkować z tabeli drugiej („prawej”). W przypadku, gdy rekordowi tabeli lewej nie będzie się dało przyporządkować wiersza tabeli prawej, to komórki zostaną wypełnione wartościami NULL.
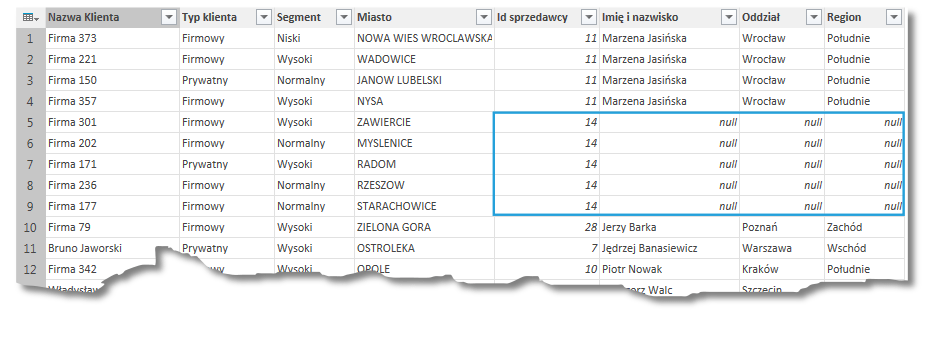
Na powyższym obrazku możemy zauważyć, iż w tabeli Sprzedawcy numerowi 14 nie był przypisany żaden sprzedawca.
– Prawe zewnętrzne (wszystkie z drugiej, pasujące z pierwszej) jest odpowiednikiem komendy RIGHT OUTER JOIN. Oznacza to, iż w tabeli wynikowej znajdą się wszystkie wiersze z tabeli drugiej oraz te, które możemy przyporządkować z tabeli pierwszej. W przypadku, gdy rekordowi z tabeli prawej nie będzie się dało przyporządkować żadnego rekordu z tabeli lewej, w komórkach pojawi się wartość NULL.
– Pełne zewnętrzne (wszystkie wiersze z obydwu) jest odpowiednikiem funkcji FULL OUTER JOIN. W tym wypadku w tabeli wynikowej znajdują się wszystkie wiersze zarówno z pierwszej, jak i drugiej tabeli. W przypadku braku odpowiednia w rekordach tabel komórki zostają wypełnione wartością NULL.
W tym wypadku nie ma znaczenia kolejność tabel – tabela wynikowa będzie zawierała te same dane (pomijając kolejność kolumn w tabeli wynikowej)

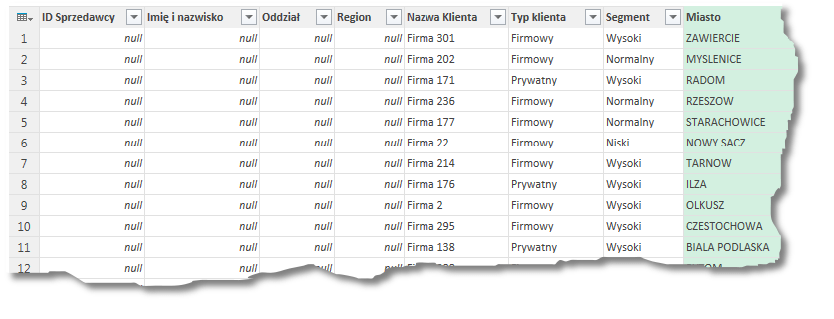
W powyższym przypadku firmie 276,356 oraz 161 nie jest przypisany żaden sprzedawca (w tabeli Klienci w kolumnie ID sprzedawcy jest numer który nie ma swojego odpowiednika w tabeli Sprzedawcy), natomiast sprzedawcy Konradowi Brożkowi nie jest przypisany żaden klient.
– Wewnętrzne (tylko pasujące wiersze) jest odpowiednikiem komendy INNER JOIN. Oznacza to, iż w tabeli wynikowej będą znajdować się wiersze z pierwszej tabeli które można powiązać z wierszami drugiej tabeli oraz wiersze z drugiej tabeli które będzie można powiązać z rekordami z pierwszej tabeli. Oznacza to, iż w tabeli wynikowej nie znajdziemy wierszy z tabeli lewej lub prawej które będą niepowiązane, a co za tym idzie – program nigdzie nie przypisze wartości NULL.
– Lewe anty (wiersze tylko w pierwszej) jest odpowiednikiem komendy LEFT ANTI JOIN. Jest to szczególny rodzaj sprzężenia, które jako tabelę wynikową zwraca wiersze, które nie są połączone w drugą – prawą tabelą.
![]()
– Prawe anty (wiersze tylko z drugiej) jest odpowiednikiem funkcji RIGHT ANTI JOIN. Analogicznie do poprzedniego sprzężenia tabelą wynikową jest zbiór wierszy niepowiązanych z pierwszą – lewą – tabelą.
Warto zwrócić na informację wyświetlającą się po najechaniu kursorem na tekst znajdujący się na dole okna Scalanie:
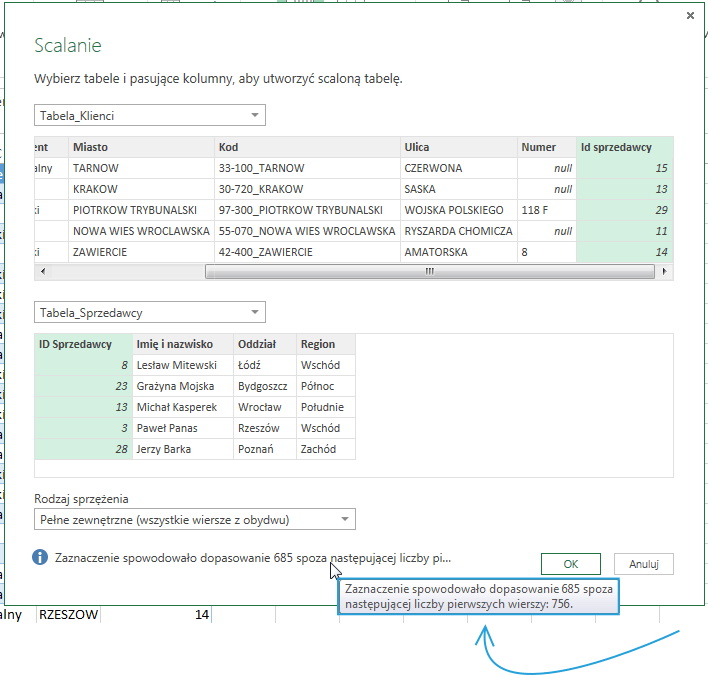
Informuje on ile wierszy jest wzajemnie dopasowanych (liczba wierszy jaką będzie miała tabela będąca efektem komendy Pełne wewnętrzne) oraz ile jest wszystkich wierszy – licząc łącznie z tymi które nie mają powiązań z drugą tabelą (liczba wierszy jaką będzie miała tabela będąca efektem sprzężenia Pełne zewnętrzne)
W Edytorze zapytań warto kliknąć w opcję Edytor zaawansowany:
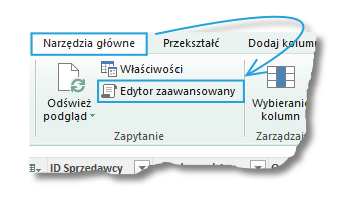
Znajdziemy tam zapytanie SQL (stąd nazwa okna) – odpowiednio doświadczony użytkownik posiadający wiedzę na temat formułowania takich zapytań może w tym miejscu ręcznie formułować odpowiednie kwerendy, dzięki czemu może otrzymywać dokładnie taką tabelę jakiej potrzebuje.
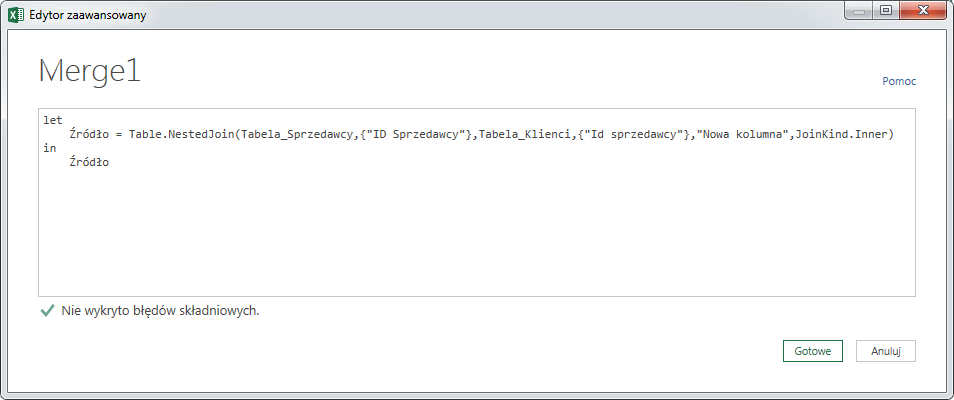
Dołączanie w Power Query
Oprócz dodawania kolumn i rozbudowy naszych tabel ”wszerz” możemy także skupić się na dodawaniu wierszy i powiększać długość tabeli. Do tego służy opcja Dołącz, obecna zarówno na wstążce Power Query we wstążce Excela, jak i w Narzędziach głównych w Edytorze zapytań:
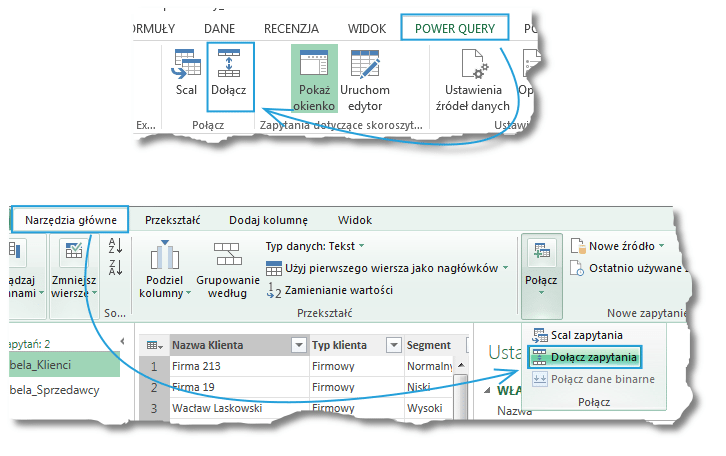
Istnieje jeszcze możliwość dołączenia tabeli poprzez kliknięcie w symbol tabeli znajdujący się w rogu tabeli podglądowej i wybranie opcji Dołącz zapytania:
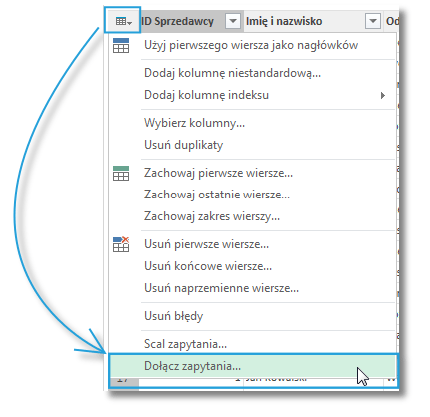
Przy pomocy przycisku w skoroszycie Excela dokonujemy dołączania pośredniego. Oznacza to, dołączenie jednej tabeli do innej stanowi nowe zapytanie. Dlatego też w w oknie zapytań pojawia nam się symbol nowej kwerendy:
W celu wykonania dołączenia pośredniego musimy wskazać dwie tabele: podstawową oraz dołączaną:
Przy pomocy przycisków w Edytorze zapytań dokonujemy dołączenia wbudowanego. Różnica polega na tym, iż nie jest tworzone nowe zapytanie, a za tabelę podstawową uznawana jest tabela aktualnie otwartego zapytania. Użytkownik wskazuje jedynie tabelę dołączaną:
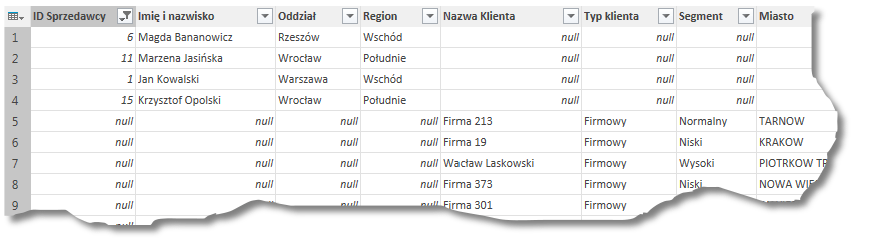
Jeżeli w procesie dołączania wybierzemy tabele o różnych nazwach kolumn, to wynikiem będzie tabela posiadająca kolumny z obu części składowych, przy czym wartości które nie istnieją przyjmą wartość NULL – tzn. wszystkie wiersze w których będą znajdowały się dane z pierwszej tabeli w kolumnach zaczerpniętych z tabeli drugiej będą puste i odwrotnie.
Przykładowo, tabele Klienci oraz Sprzedawcy nie zawierają żadnych wspólnych kolumn, więc efekt końcowy będzie podobny do tego:
W przypadku gdy tabele z łączonych nazywają się dokładnie tak samo następuje po prostu zwiększenie liczby wierszy tabeli podstawowe o rekordy z tabeli dołączanej.
Podsumowanie
Choć scalanie po części pokrywa się z funkcjonalnością formuły WYSZUKAJ.PIONOWO oraz dodatku Power Pivot, a dołączanie można łatwo obejść poprzez po prostu odpowiednie kopiowanie i wklejanie, to należy pamiętać o kilku wyróżniających dodatek Power Query faktach:
– Po pierwsze, aby mieć dodatek do Power Pivot należy zakupić pakiet Office Professional Plus lub usługę Office 365. Do Power Query potrzeba jedynie podstawowej wersji Excela 2010, 2013 lub wyższej, co wiąże się ze sporymi oszczędnościami;
– przy opcji scalania mamy do wyboru wiele różnych sprzężeń – wyniki jakie z łatwością uzyskujemy przy pomocy Power Query przy takich sprzężeniach jak np. wewnętrzne są co najmniej trudne do otrzymania przy zastosowaniu innych technik;
– system importowania danych i odświeżania zapytań gwarantuje nam aktualność tabeli wynikowej w przypadku zmiany danych źródłowych.
Powyższe cechy powodują, iż Power Query może okazać się dodatkiem bardzo przydatnym – szczególnie w przedsiębiorstwach w których różne osoby są odpowiedzialne za uzupełnianie danych w różnorakich skoroszytach, ale potem następuje ich agregacja (np. właśnie poprzez Power Query) w jednym pliku.
Jakie jest Wasze zdanie w tej kwestii? Podzielcie się nim w komentarzach!
Ps. Dane które posłużyły do napisania powyższego artykułu można znaleźć tutaj.




Bardzo pomocny artykuł, dziękuję! Powiedz mi jeszcze Bartek, jak dorzucić jako dodatkowa kolumna nazwę tabeli, z której pochodzą te dane?
Chodzi oczywiście o dołączanie danych
Niestety nie ma żadnego automatycznego sposobu; można to zrobić poprzez dodanie dodatkowej kolumny do tabel z ich nazwą przed wykonaniem dołączania – w oknie Power Query wybieramy zakładkę „Dodaj kolumnę”, następnie opcja „Dodawanie kolumny niestandardowej”. Pojawi się okno, w którym definiujemy nazwę kolumny i jej zawartość. Tekst należy wpisać w cudzysłowie (np. =”Nazwa tabeli”)
Czy istnieje możliwość jednoczesnego scalania kilku tabel w power query?
Niestety nie ma; można naturalnie scalać tabele po kolei, tj: najpierw dwie tabele, następnie tabelę powstałą ze scalenia i kolejną tabelę i tak dalej.
A jeśli chodzi o dołączanie, można posłużyć się pobieraniem z folderów, przykład w artykule:
Pobieranie danych z folderu
Dzień dobry,
Funkcja Wyszukaj.pionowo na podstawie zastosowanego klucza (np. nr zamówienia lub innej kombinacji) podaje tyko jedną/pierwszą wartość z przeszukiwanego zakresu.
Jeżeli wykorzystuję funkcję scalania PQ dwóch tabel na podstawie klucza, przy czym w drugiej tabeli dla tego samego klucza jest kilka wyników/wierszy, to po połączeniu, dane z pierwszej tabeli powielają się. Nie mam możliwości zastosowania bardziej szczegółowego klucza , a chciałabym, aby wiersze z pierwszej tabeli nie powielały się (są unikalne), tylko np. wyniki z tabeli dołączanej trafiały do odpowiednich wierszy w kilku kolumnach (w ilości odpowiadającej wielokrotności występowania klucza w drugiej tabeli, tzn. do klucza z tabeli 1, odpowiadają 3 wyniki z tabeli 2, więc trafiają one do 3 kolumn (a nie zwielokrotniają liczbę wierszy z tabeli 1 do trzech).
Czy istnieje taka możliwość ?
Dziękuję,
Świetne pytanie. Istnieje taka możliwość, a realizuje ją się podobnie do sposobu opisanego w artykule:
Jak scalić tekstowo wiersze w Power Query?: https://excelbi.pl/scal-wiersze-w-kolumnie-w-power-query/
A szczegółowo:
1. Wykonujemy scalanie, ale nie rozpakowujemy, trzymając scaloną tabelę w kolumnie Table.
2. Usuwamy z tabel niepotrzebne kolumny
3. Konwertujemy tabelę na listę
4. Łączymy teksty.
Bartek, nie żebym się czepiał, jednak uważam że to dość ułomny sposób otrzymania tego czego oczekuje Paulina.
Oczywiście, jest możliwym otrzymanie wyników w kolumnach ( jak oczekuje Paulina) jednak wyklikać się tego nie da. Na tym etapie potrzeba juz trochę wiedzy o języku M (którego używa Power Query). Jego znajomość (choćby częściowa) otwiera przed nami zupełnie nowy (M-agiczny) świat możliwości nieporównanie większych niż daje nam wyłącznie interfejs użytkownika (choć i on już daje wiele) :-)))
Pozdrawiam
Bill Szysz
Pewnie tak Ale ja zawsze szukam najpierw „wyklikiwanych” odpowiedzi :))
Ale ja zawsze szukam najpierw „wyklikiwanych” odpowiedzi :))
Witam,
Ja mam pytanie odnośnie praktyk stosowanych w power query.
Pobieram dane z systemu co tydzień w celu aktualizacji (dane od stycznia do grudnia) z x modułów i je łącze ze sobą.
W związku z tym, że dużo kroków z tego wychodzi i jest dużo funkcji, rekordów to wyrzucam je jako tabela w pierwszym pliku.
Następnie plik drugi – główny pobiera te dane z pierwszego i wyrzucam je do tabeli przestawnej. Plik drugi główny pobiera dane z innych plików. Robiąc takie podejście chciałem optymalizować i przyspieszyć odświeżanie w pliku drugim. Jest to dobre podejście/optymalizacja czy są inne stosowane?
Hej Mateusz, jest to sensowne podejście dla dużej liczby zapytań, kroków i plików lokalnych. Są też inne sposoby optymalizacji zapytań, ale zwykle wymagają pracy w kodzie. Polecam w tym zakresie przejrzeć jeszcze dobre praktyki we wpisie: https://excelbi.pl/11-pomyslow-jak-przyspieszyc-zapytania-w-power-query/ + blog https://blog.crossjoin.co.uk.
Witam serdecznie. Potrzebuję łączyć wiele plików excel z wieloma arkuszami w jeden zbiorczy plik bez korzystania z VBA! Tabelki w tych plikach źródłowych są o podobnym układzie, lecz nie identyczne (mają jednolite tytuły kolumn, lecz kolejność kolumn może być czasami różna, czasami jakiś tytuł się pojawia, innym razem nie, bo w miejsce tego tytułu jest inny). Potrafię to zrobić przez dodanie niestandardowej kolumny z funkcją Excel.Workbook z argumentem true. Niestety w moich źródłowych tabelkach wiersze nagłówkowe kolumn są dopiero w 3 wierszu. Czy można coś zrobić, aby w trakcie przekształcania w PQ był promowany ten 3 wiersz jako nagłówki? Czy jestem skazana na ręczne usuwanie tych pierwszych wierszy w plikach źródłowych przed załadowanie do PQ?
Cześć Jola, dzięki za pytanie. Stawiam, że chodzi o operację Dołączanie, którą polecam zrealizować poprzez pobieranie danych z folderu.
Krok 1: Zbuduj folder z plikami
Krok 2: W nowym pliku Excel wybierz Pobierz dane > Z folderu
Krok 3: Postępuj zgodnie z instrukcją w webinarze:
https://excelbi.pl/jak-pobierac-do-excela-i-power-bi-pliki-z-folderu-z-power-query-webinar-z-1-10-2020-wideo/
Twój scenariusz będzie wymagał prawdopodobnie modyfikacji przykładowego zapytania. W dalszej części webinaru pokazałem przykład z usuwaniem pierwszych wierszy, aby dołączanie odbyło się po właściwych nagłówkach.
Powodzenia!
Dzień dobry,
czy istnieje możliwość scalenia tabel znajdujących się w zakładce o jednakowej nawie w różnych plikach, tak by tabele były dołączane obok siebie (nie pod sobą)?
Hej Marta, tak. Po prostu wczytaj 2 zapytania osobno i wykonaj Scalanie (nie Dołączanie) po jakimś kluczu albo po wszystkich kolumnach na raz.
Dzień dobry,
W jaki sposób dzięki PQ dołączyć do tabeli, która zawiera kolumnę z tekstem, drugą tabelę z danymi, na podstawie części tekstu z pierwszej?
Nie ma możliwości podziału tekstu w pierwszej tabeli na podstawie ogranicznika, liczby znaków, pozycji (jest za każdym razem inny).
Jedynym rozwiązaniem wydaje się być stworzenie tabeli pomocniczej z wybraną częścią tekstu, przyporządkowaniem jej danych, które miałyby odpowiadać danemu fragmentowi tekstu i połączeniem tych tabel.
Czytałam o dopasowaniu rozmytym, ale w moim przykładzie nie znajduje dopasowań. Czy istnieje jakieś rozwiązanie?
Dziękuję,
Hej Paulina, świetne pytanie,na które nie znam jeszcze dobrej odpowiedzi. Sensowny sposób to stworzenie kolumny, o której piszesz. Próbowałem kiedyś scalać każdy wiersz z każdym i budować kolumnę warunkową „czy zawiera tekst” i wtedy dopiero zakładać filtr. Ale to było powolne.
Niemniej zerknij też tu: https://p3adaptive.com/2019/02/powerquerymagic-conditional-joins-using-table-selectrows/
Bardzo dziękuję za link i podpowiedź. To działa! i właśnie tego potrzebowałam.
Dzień dobry,
Czy istnieje rozwiązanie na scalanie, które działa dokładnie jak wyszukaj.pionowo? Tak, aby na podstawie zastosowanego klucza zwracało tylko jedną/pierwszą wartość z przeszukiwanego zakresu?
Jeżeli istnieje kilka powtarzających się rekordów w drugiej tabeli, to przy scaleniu powiela mi rekordy z pierwszej, a chciałabym żeby dane z pierwszej tabeli pozostały bez zmian.
Hej Kasia, przed scalaniem usuń duplikaty z tabeli, w której wyszukujesz. W ten sposób klucz będzie w tabeli „prawej” tylko 1 raz i scalanie = WYSZUKAJ.PIONOWO.