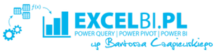




Nowa wizualizacja Power BI o nazwie Key incluencers pozwala szukać odpowiedzi na najczęściej nurtujące nas pytania analityczne: Co wpłynęło na to, że klient ocenił Cię pozytywnie w ankiecie ewaluacyjnej? Przez co w tym kwartale sprzedaż była ponadprzeciętna? Co sprawia, że klienci lubią akurat ten produkt? Co jest ważne, a co też ważne, ale trochę mniej? Jakie grupy klientów możesz u siebie wyróżnić? Odpowiedzi może dostarczyć autoanaliza właśnie z wykorzystaniem Key influencers.
Założenia przed startem z Key influencers
Oto kilka założeń okiem statystyka:
- Zmienna objaśniana musi być zmienną jakościową. Metoda nie przyjmie np. kolumny z wysokością zysku lub sprzedaży; najpierw musiałbyś podzielić ją co najmniej na przedziały.
- Zmienna objaśniana jest traktowana zero-jedynkowo. W interfejsie Key influencers wybierasz poziom, który chcesz objaśnić, np. to, że klient wystawił Ci 5 w ankiecie ewaluacyjnej. Pozostałe możliwości są traktowane jako jedno, czyli to, że dostałeś 4,5 oznacza dokładnie to samo, co gdybyś dostał ocenę 1. Staraj się zatem doprowadzać dane do stanu, w którym będziesz miał tylko dwie możliwości wyboru – coś jest zadowalające albo nie.
- Ze względu na sposób testowania istotności modelu pamiętaj, że przy modelu logitowym powinieneś mieć duży zbiór danych.
Uwaga, by nie przekłamać sobie wyników!
Co sprawia, że produkt jest nisko oceniany?
Dzisiejszy przykład tylko dla pełnoletnich :). Ze strony data.world można pobrać oceny piw dokonane przez użytkowników portalu BeerAdvocate. Jest ich bagatela 1,5 miliona i dotyczą okresu co najmniej 10-letniego do listopada 2011. Użytkownicy portalu oceniali trunki w skali od 0 do 5 (w skali co 0.5 punktu) w 5 kategoriach, w tym w kategorii ogólna ocena. Poza tym w bazie znajdziemy informacje o nazwie ocenianego piwa, browarze oraz login oceniającego. Postaramy się wyjaśnić, co wpływa na to, że użytkownik oceniał piwo dobrze albo źle. Zaczynamy!
Jak zostać ekonometrykiem w kilku kliknięciach?
Przede wszystkim włącz opcję Key influencers. Jak każdy nowy dodatek typu preview, trzeba go włączyć ręcznie. Kliknij Plik > Opcje i ustawienia > Opcje > Funkcje w wersji zapoznawczej > Wizualizacja Kluczowe elementy mające wpływ, a następnie zatwierdź OK. Power BI się zrestartuje i przystąpimy do pracy.
 Ikonka Kluczowe czynniki mające wpływ pojawi się w panelu Wizualizacje tuż za R i przed globusem.
Ikonka Kluczowe czynniki mające wpływ pojawi się w panelu Wizualizacje tuż za R i przed globusem.
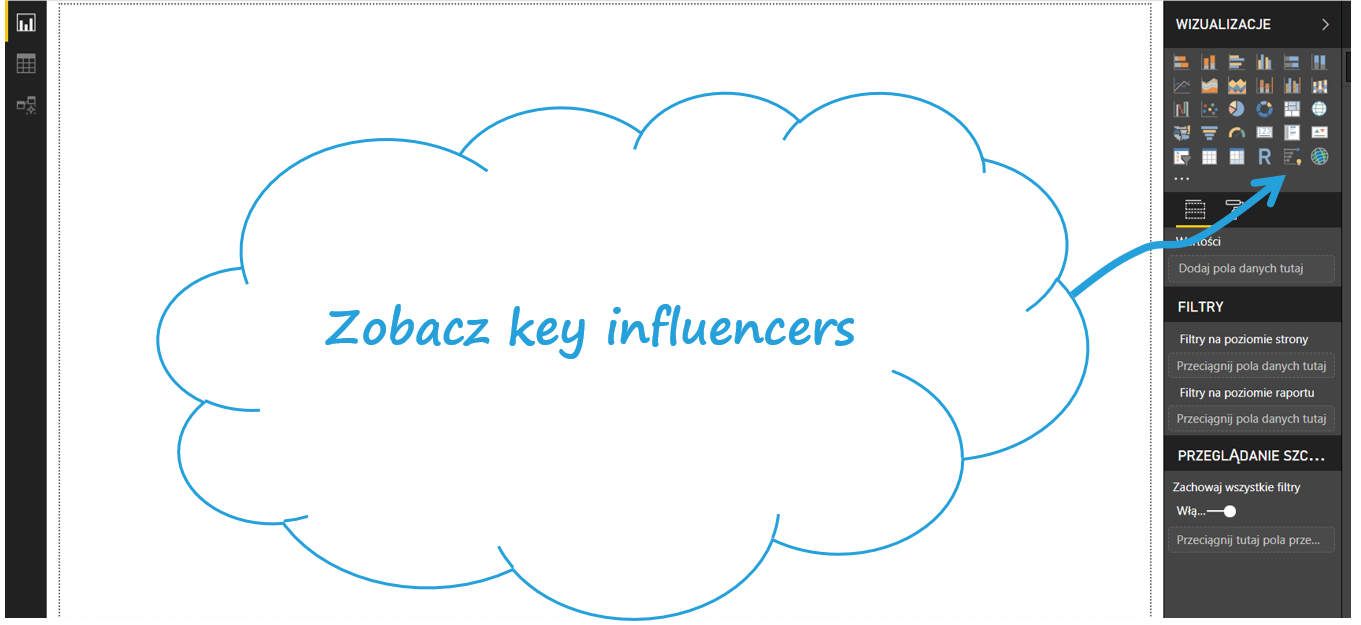 Następnie wgrywam dane: pobrane z data.world oraz ręcznie przygotowany słownik na podstawie zakładki Beers > Beer Styles na stronie BeerAdvocate. Niestety nie wszystkie kategorie piw są tu wyszczególnione, niektóre nazwy nie są dokładne, więc zastosowałem fuzzy merge (możecie o tym poczytać w tym artykule) przy domyślnym progu podobieństwa i zwracających maksymalnie 1 dopasowanie. Tam, gdzie jednak żadna kategoria się nie dopasowała, zamieniłem brak danych na kategorię Inne (Other). W kolejnym kroku na podstawie kolumny z ogólną oceną napoju tworzę kolumnę z informacją, czy ogólna ocena piwa była wysoka, czy niska (HighOverall). Jeśli użytkownik wystawił ocenę wyższą niż 3, piwo jest oceniane wysoko. Jeśli nie, nisko.
Następnie wgrywam dane: pobrane z data.world oraz ręcznie przygotowany słownik na podstawie zakładki Beers > Beer Styles na stronie BeerAdvocate. Niestety nie wszystkie kategorie piw są tu wyszczególnione, niektóre nazwy nie są dokładne, więc zastosowałem fuzzy merge (możecie o tym poczytać w tym artykule) przy domyślnym progu podobieństwa i zwracających maksymalnie 1 dopasowanie. Tam, gdzie jednak żadna kategoria się nie dopasowała, zamieniłem brak danych na kategorię Inne (Other). W kolejnym kroku na podstawie kolumny z ogólną oceną napoju tworzę kolumnę z informacją, czy ogólna ocena piwa była wysoka, czy niska (HighOverall). Jeśli użytkownik wystawił ocenę wyższą niż 3, piwo jest oceniane wysoko. Jeśli nie, nisko.
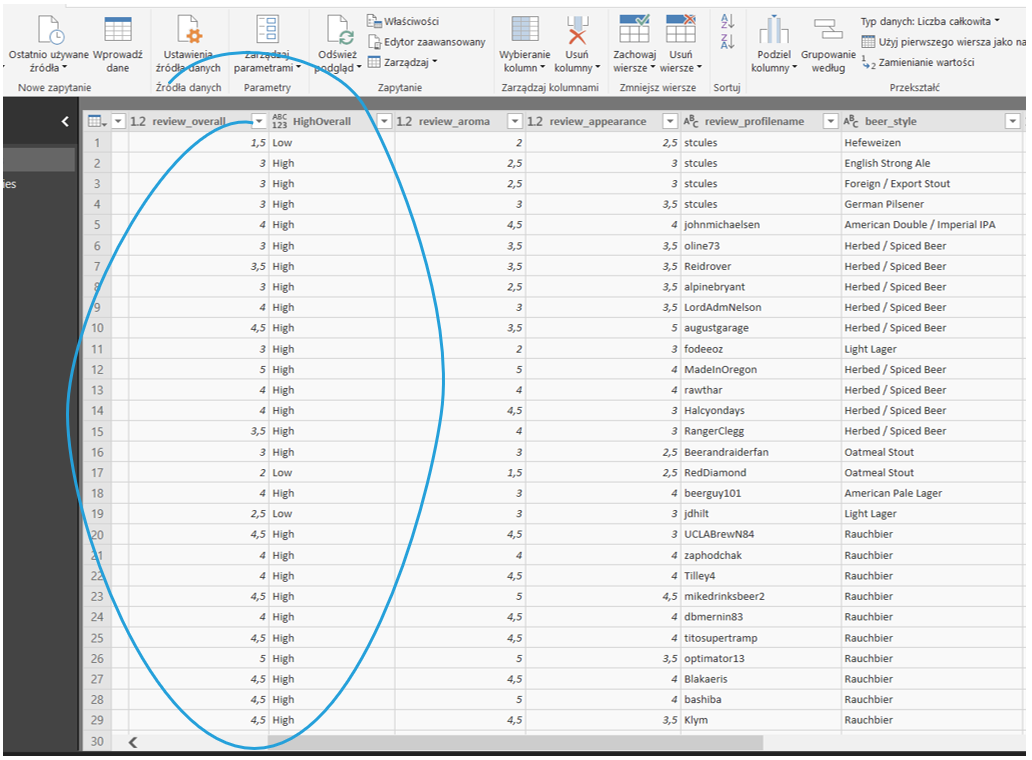
Tak przygotowane dane ładuję do Power BI i zaczynam modelowanie!
W panelu Wizualizacja klikam na Kluczowe elementy mające wpływ.

Pojawia się wizualizacja, a po prawej pola do uzupełnienia odpowiednimi kolumnami. Do okienka Analizuj przenoszę kolumnę HighOverall, a do Wyjaśnij według póki co wszystkie kolumny opisujące piwo. Power BI w locie analizuje zmienne i pokazuje te, które mają najsilniejszy wpływ.
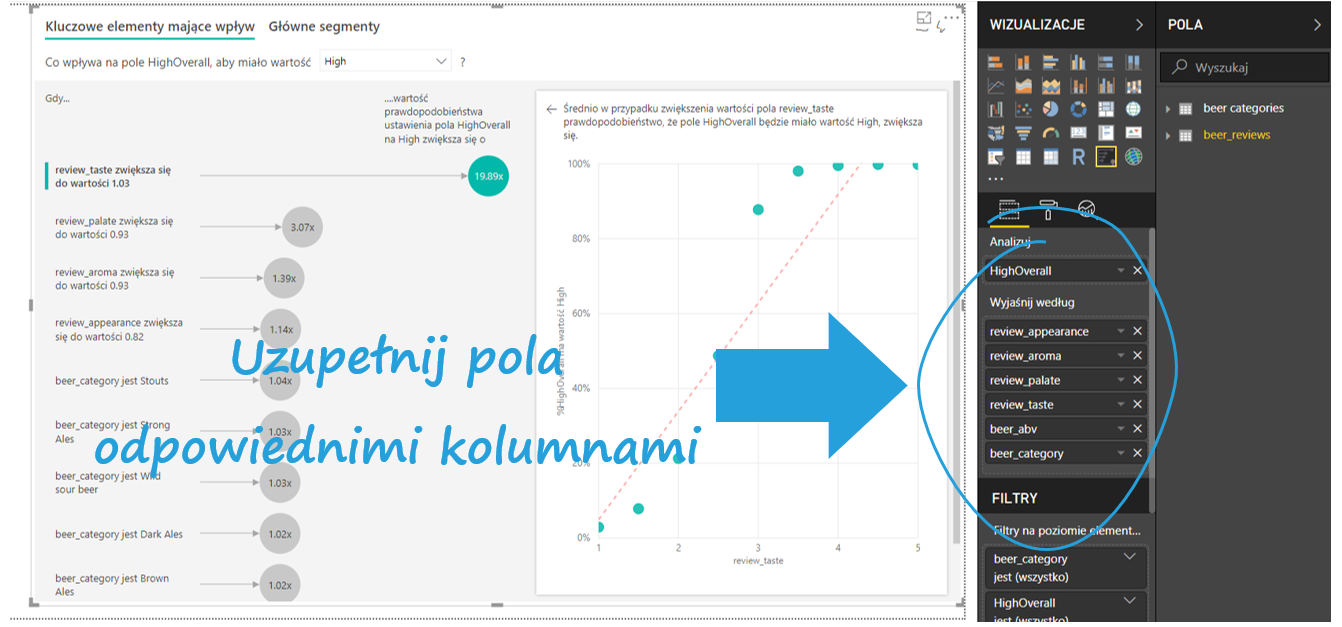
Na razie Power BI szuka najlepszych czynników, które powiedzą, dlaczego klient ocenił piwo wysoko. Możemy to zmienić na ocenę niską na wybieranej liście po lewej stronie grafiki.
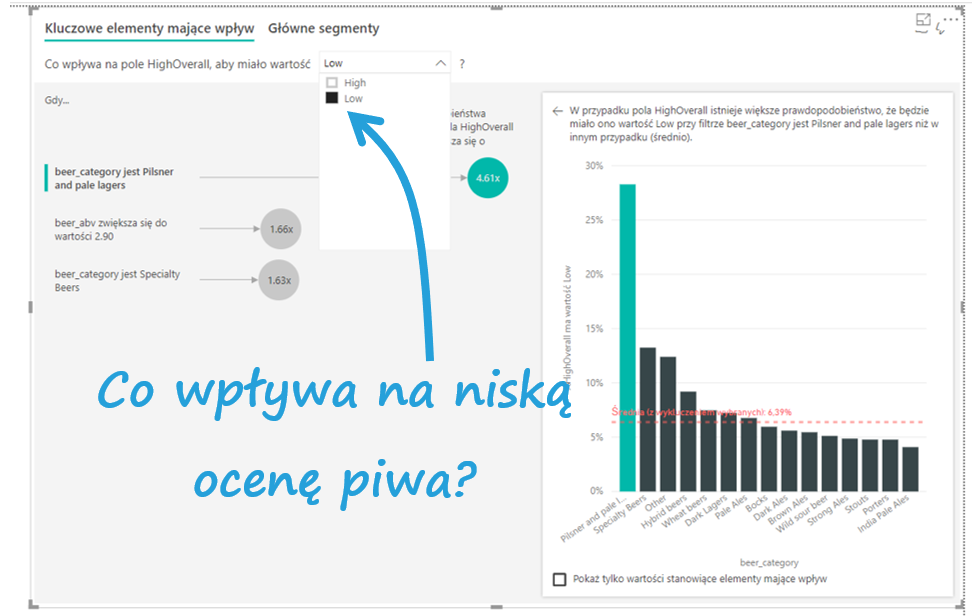
Wizualizacja jest prosta, ale zawiera dużo informacji. W górnym lewym rogu mamy możliwość wybrania, czy chcemy mieć widok na kluczowe elementy czy na segmentację klientów. Zinterpretujmy wyniki.
Czego dowiemy się z analizy kluczowych elementów?
Bąble po lewej stronie to kluczowe czynniki mające wpływ na, w tym przypadku, niską ocenę piwa przez użytkowników.
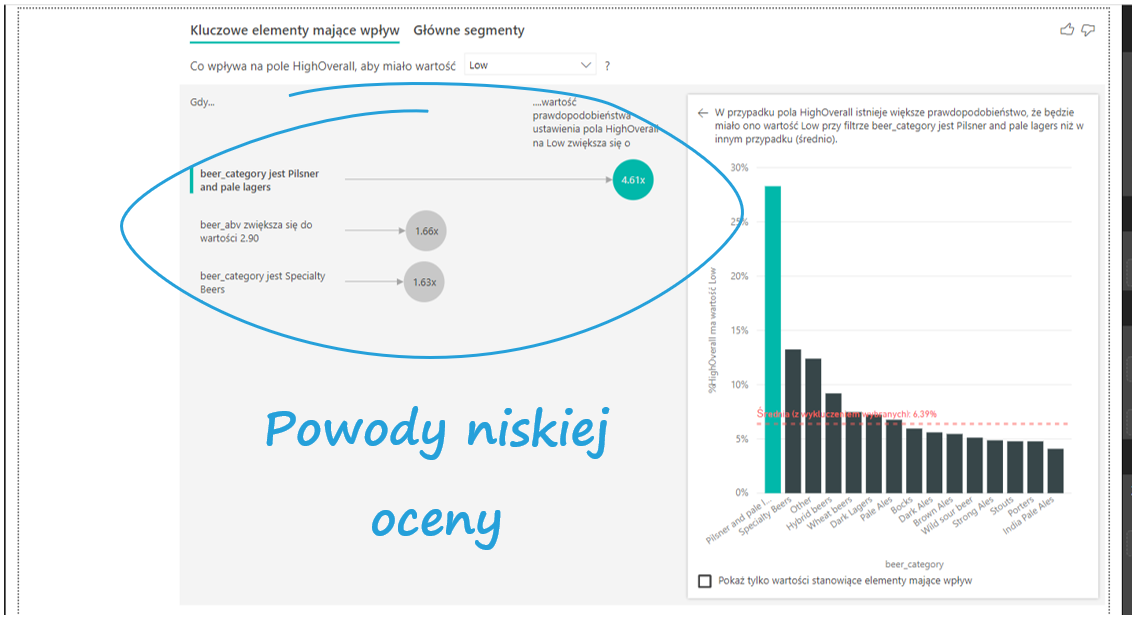
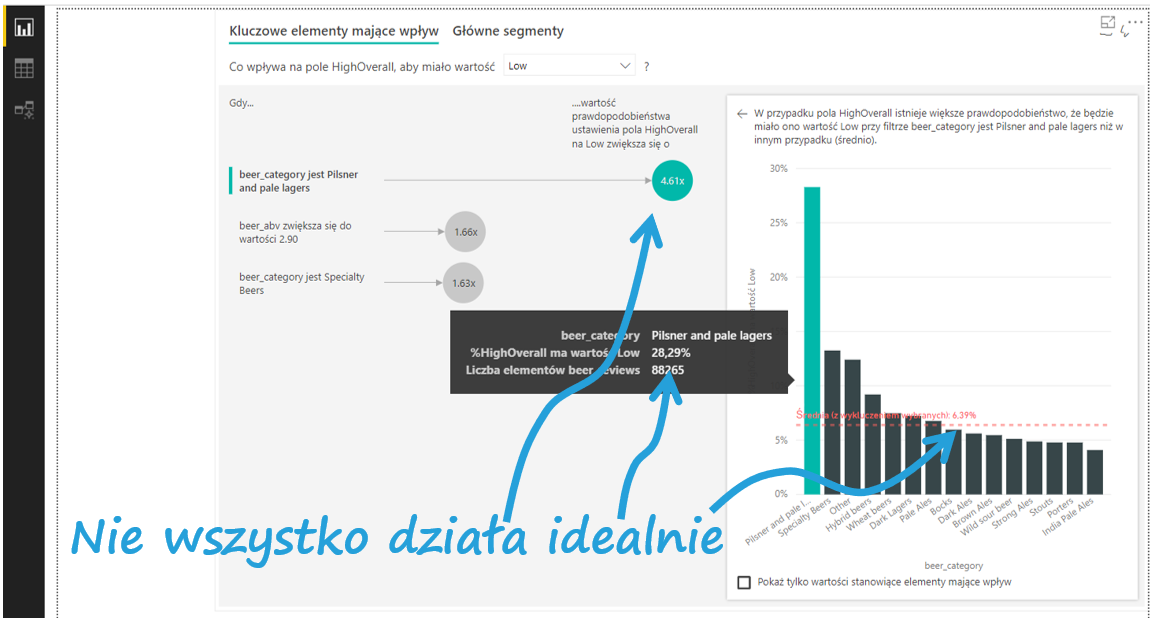
Interpretacja jest intuicyjna – najważniejszy jest fakt oceny piwa z kategorii Pilsner and pale lagers. Power BI umożliwia odczytywanie wyników pełnymi zdaniami: gdy beer_category jest Pilsner and pale lagers wartość prawdopodobieństwa ustawienia pola HighOverall na Low zwiększa się 4,61 razy. Co to znaczy? Oceny wystawione piwom w kategorii Pilsner and pale lagers mają 4,61 razy wyższe prawdopodobieństwo negatywnych ocen niż przeciętnie pozostałe kategorie piw. Po prawej stronie pojawia się wykres, na którym widzimy odsetki negatywnych ocen dla poszczególnych stylów piw. Zgodnie z opisem interpretacji na stronie Power BI (znajdziesz go tu), powinno być tak, że jeśli pomnożymy wartość średnią na czerwonej linii przez 4,61, powinien wyjść odsetek negatywnych ocen dla piw Pilsner and pale lagers. Niestety w tym przypadku to nie działa.
Jako że kategorii piwa jest dużo, warto na wykresie pokazać tylko te, które pojawiają się w bąbelkach. Wystarczy kliknąć Pokaż tylko wartości stanowiące elementy mające wpływ, by pokazały się tylko istotne czynniki.
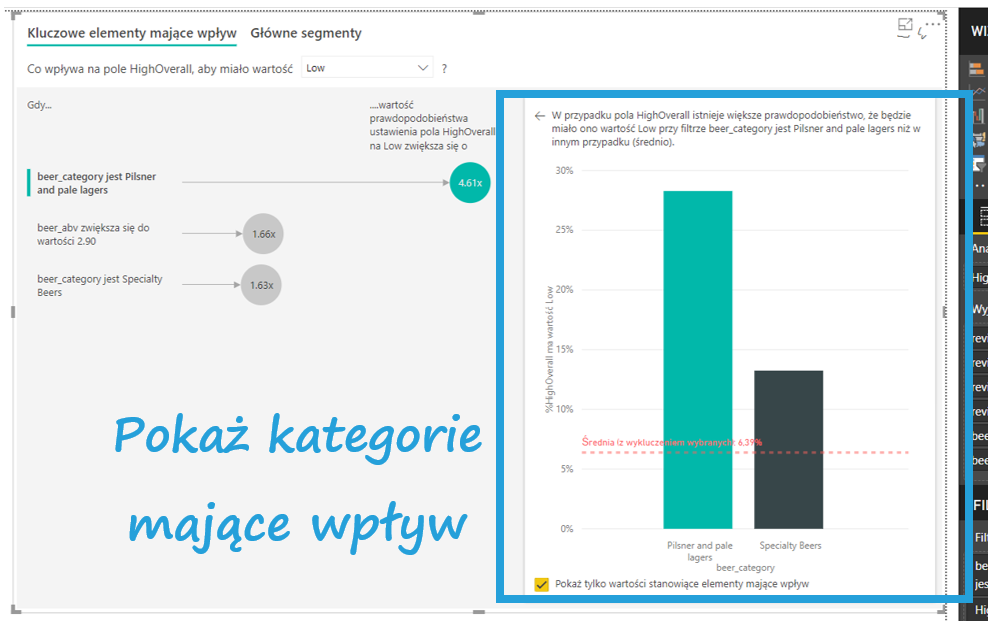 Na liście możemy znaleźć nie tylko zmienne związane ze kategorią piwa – ważna okazała się też zawartość alkoholu w produkcie.
Na liście możemy znaleźć nie tylko zmienne związane ze kategorią piwa – ważna okazała się też zawartość alkoholu w produkcie.
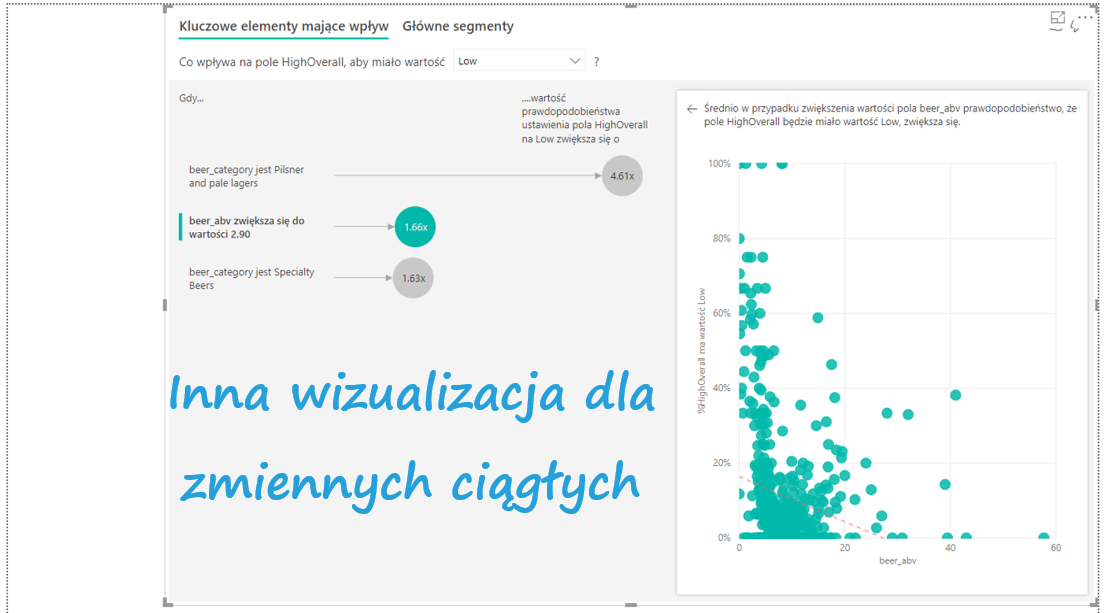
Od razu zmienił się też typ wizualizacji – procentowa zawartość alkoholu w piwie jest zmienną ciągłą. Okazuje się, że mniej procentowe piwa mają raczej niższe oceny, a progiem jest 2,9. W tym przypadku oznacza to, że ilekroć piwo ma mniej alkoholu o 2,9, prawdopodobieństwo niskiej oceny zwiększa się x 1,5.
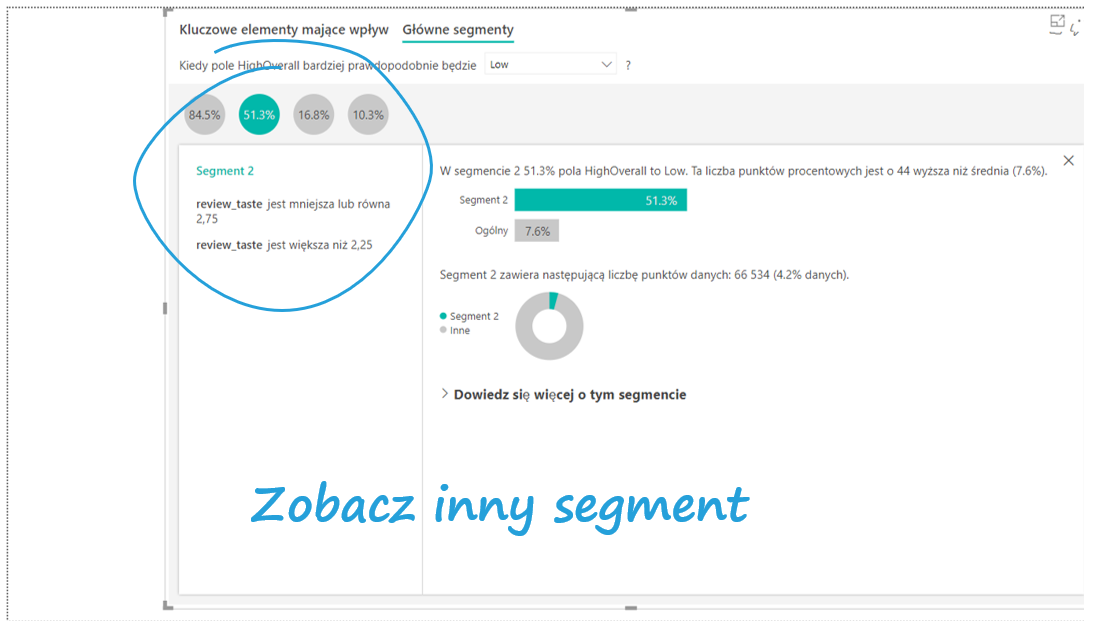
Przejdźmy do segmentów klientów.
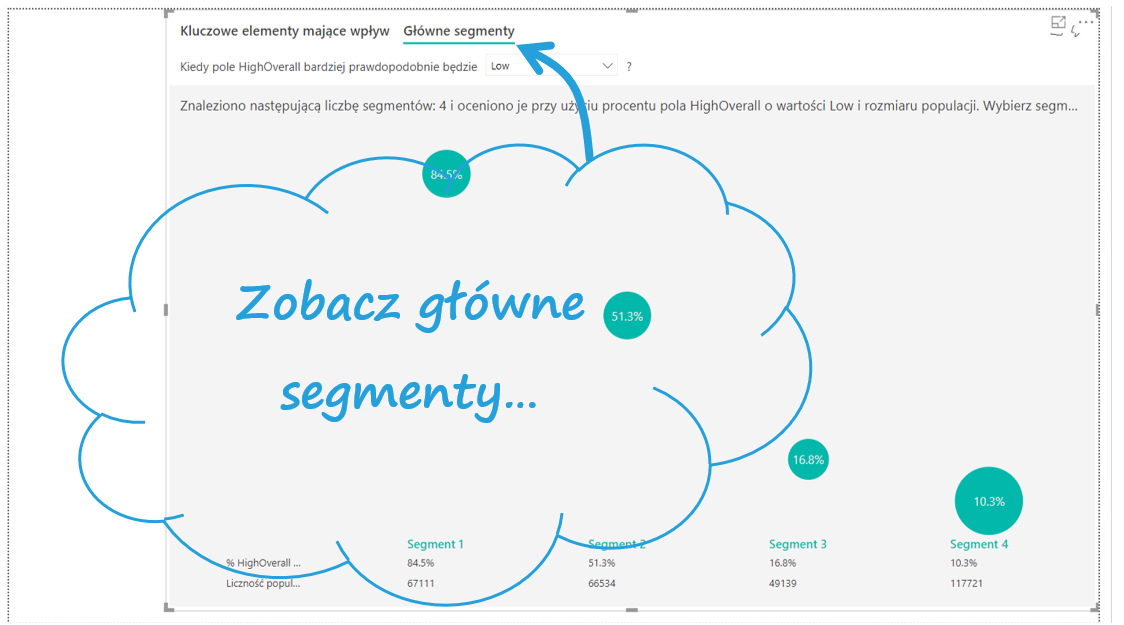
Power BI podzielił klientów na 4 grupy różniące się odsetkiem osób niezadowolonych. Wielkości bąbelków sugerują liczności poszczególnych grup. Gdy klikniemy na interesujący nas bąbelek, dowiemy się szczegółów o danym segmencie.
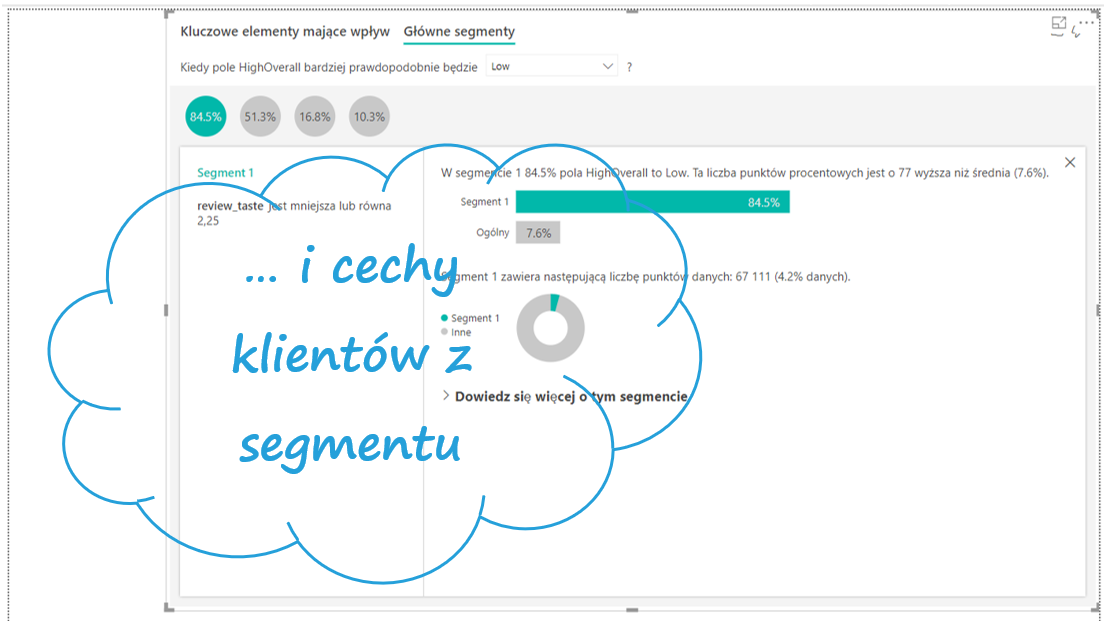
Czytając informacje od lewej strony dowiadujemy się, że są to klienci, którzy ocenili smak piwa poniżej poziomu 2,25. Grupa ta składa się w 84,5% z osób negatywnie oceniających piwo, co jest wyższe od udziału negatywnych ocen w całej bazie o 77 punktów procentowych, i składa się z ponad 67 tys. obserwacji. Analogiczne informacje zawiera kolejny bąbelek.
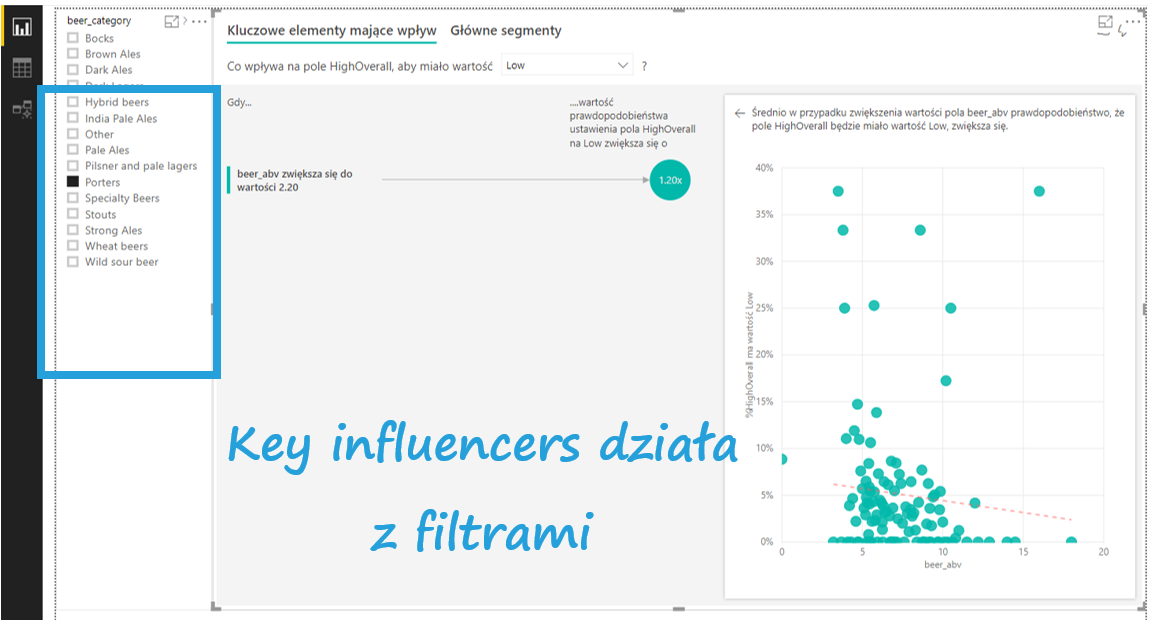
Wizualizacja współgra także np. z filtrami. Wstaw filtr tak, jak następną wizualizację i zobacz, jakie cechy ma Porter, który jest nisko oceniany.
Poczekajmy na wersję finalną
Strona Power BI oraz polskie tłumaczenie sugerują interpretację wartości w bąbelkach w kategorii prawdopodobieństwa. Budzi to jednak wątpliwości, gdyż mechanizm pod spodem jest nietransparentny i na razie nie wszystko się na wykresie zgadza. Niemniej ta autoanaliza (obok wyjaśniania wzrostu oraz wyjaśniania dystrybucji) z pewnością stanie się stałym punktem w pracy z Power BI i jeszcze do niej na blogu wrócimy.



