


Operacja unpivot, przetłumaczona w Power Query jako Anuluj przestawienie kolumn, niejedno ma oblicze. Jednym z ostatnich scenariuszy, realizowanym warsztatowo na szkoleniu Excel BI w pracy analityka, był unpivot z dwupoziomowymi nagłówkami oraz dużą liczbą wierszy i kolumn. Oto propozycja jego rozwiązania.
Dane źródłowe w programie Excel
Dane mają postać tabeli, w której dla każdej kategorii (A, B itd.) dane nt. 4 wskaźników dla różnych ID lecą w prawo.
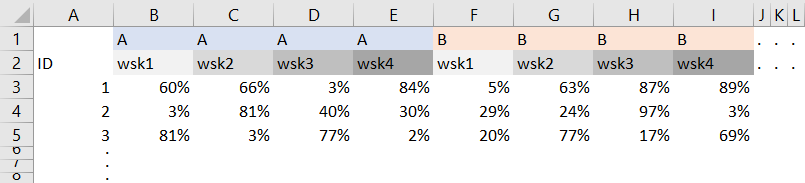
Liczba kategorii wynosi kilkaset, zaś liczba ID sięga kilku tysięcy, więc sposób na unpivot, omawiany kiedyś na meetupie, nie wchodzi w rachubę, gdyż powstałoby zbyt wiele kolumn w momencie transponowania tabeli. W związku z tym rozdzielimy proces na dwa zapytania i oddzielnie przeprocesujemy nagłówki, a oddzielnie dane.
Krok 1: Wczytaj dane do Power Query
Tworzymy nowe zapytanie do pliku z danymi.

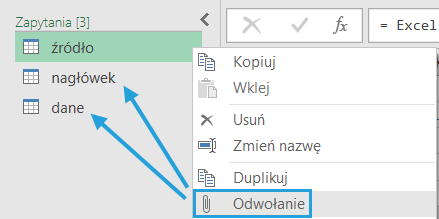
Krok 2: Zrób odwołanie na proces dla nagłówka i danych
Tworzymy odwołanie do zapytania źródłowego i rozdzielamy proces na 2 ścieżki: nagłówka i danych.
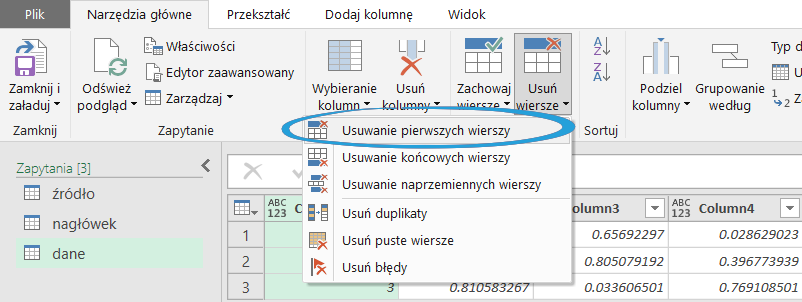
Następnie usuwamy w obu zapytaniach niepotrzebne wiersze. W moim scenariuszu było to:
- Pozostawienie 2 wierszy dla nagłówka:
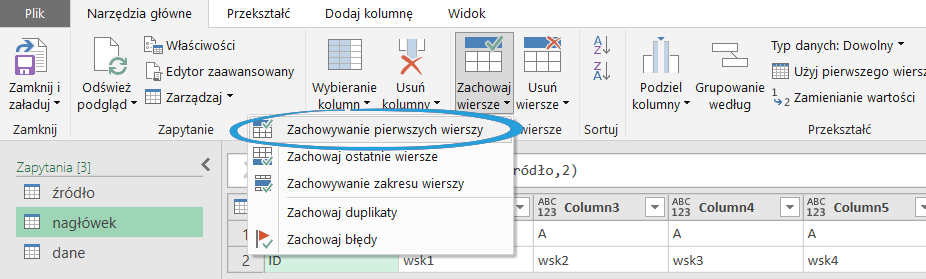
- Usunięcie 2 wierszy dla danych:
Krok 3: Przygotuj złączony nagłówek
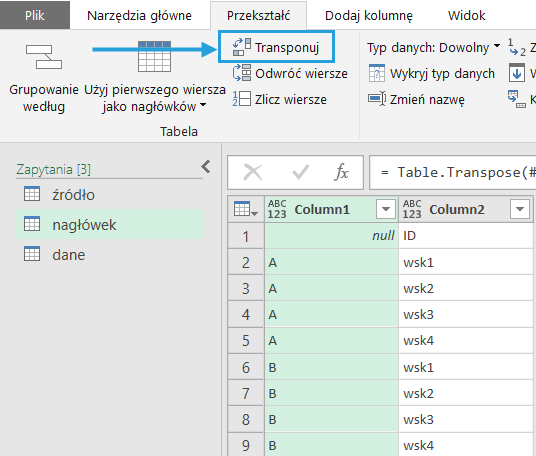
Czas na złączenie danych dla nagłówka do jednej kolumny. Najpierw wykonujemy transpozycję.
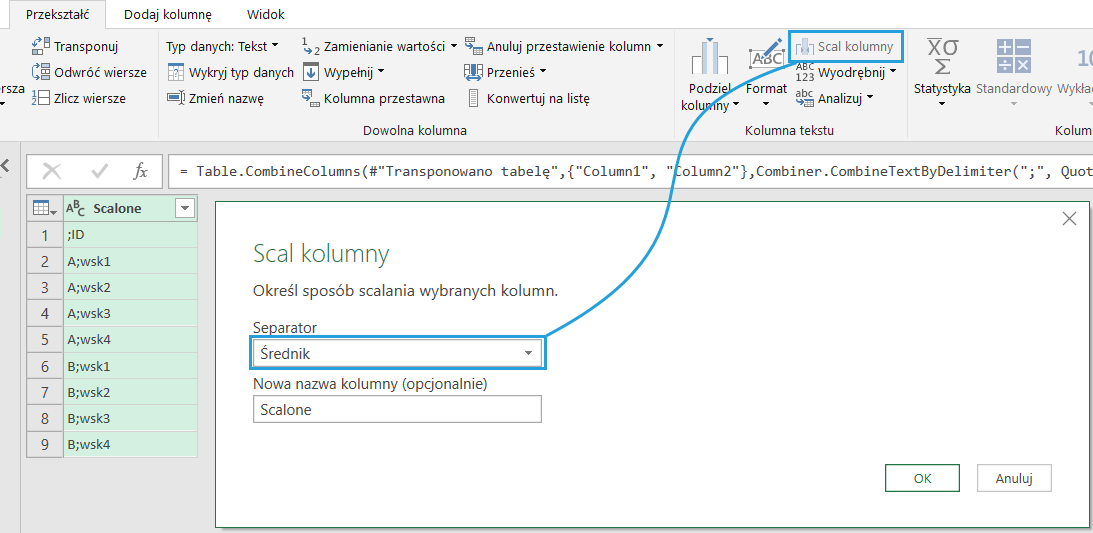
Następnie tworzymy kolumnę scaloną z separatorem jako średnikiem.
A na koniec ją ponownie transponujemy 

Krok 4: Dołącz dane do nowego nagłówka
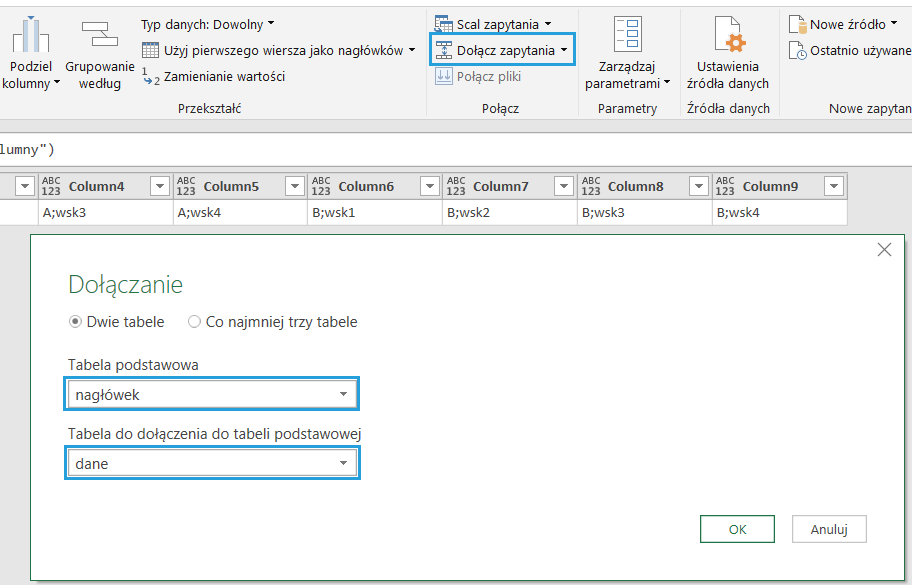
Teraz łączymy dane ponownie w całość operacją Dołącz, zaczynając od nagłówka, a kończąc na danych.
Zapytanie wygląda teraz następująco.

Krok 5: Unpivot
Nadajemy nagłówki i wykonujemy Unpivot others, czyli Anuluj przestawienie innych kolumn.
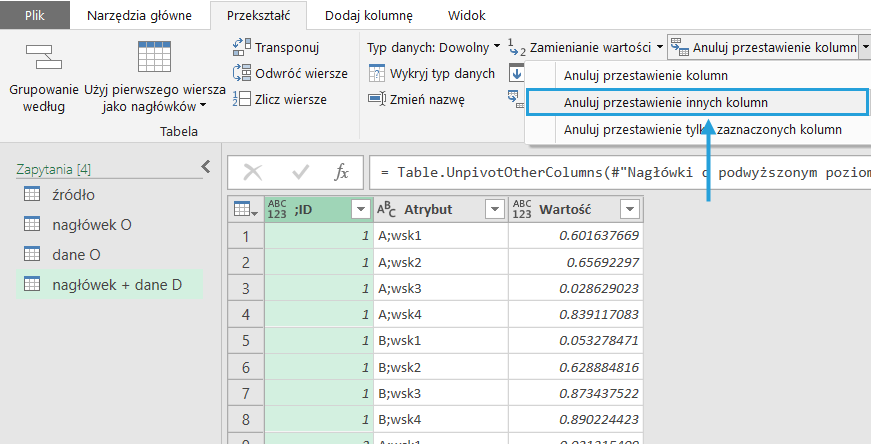
Krok 6: Rozdziel kolumny
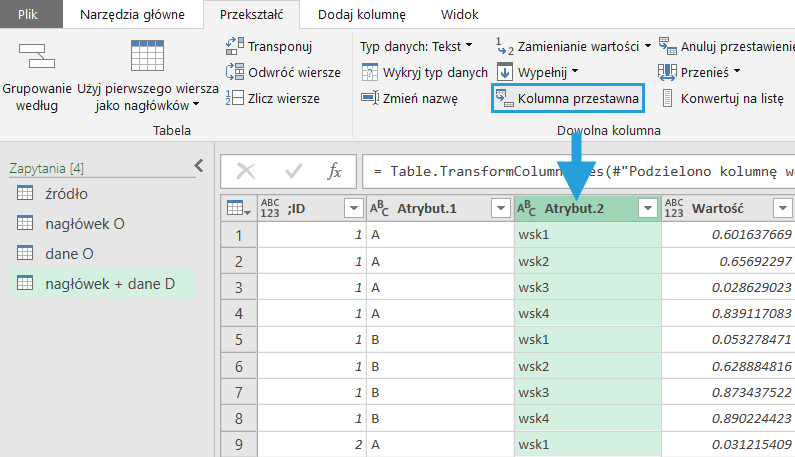
Dzielimy kolumnę wg ogranicznika.

Krok 7: Kolumna przestawna, czyli wtórny pivot
Teraz wykonujemy operację tworzenia kolumn przestawnych na kolumnie ze wskaźnikami, wskazując wartość jako kolumnę obliczeniową.
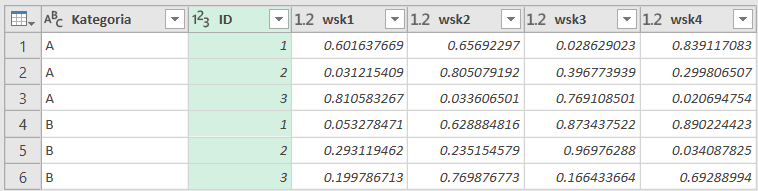
Krok 8: Zmień nazwy kolumn
Na koniec zmieniamy nazwy kolumn na właściwe i ładujemy dane do tabeli przestawnej, Power Pivot lub Power BI.
Pobierz plik Excel z zapytaniem w Power Query
Tu możesz pobrać plik Excel i prześledzić wszystkie kroki w zaawansowanym unpivocie.




Po co zostaje zachowana kolumna „ID”? Czy jest ona potrzebna?
Kolumna ID w pierwotnym przykładzie to nie była zwykła numeracja wierszy tylko pole merytoryczne (Grupa materiałowa), które było niezbędne.
hej,
jak usuniemy istniejącą kolumnę to proces ładowania się wywraca.. jak to zabezpieczyć?
Upewnij się, że nigdzie w kodzie nie pojawiają się nazwy kolumn, np. w kroku typu Zmieniono typ. Jeśli nadal będziesz miał problem, podeślij plik.
hmm.. ale wystarczy z Twojego pliku źródłowego usunąć pierwszą lepszą kolumne i odświeżenie danych się wywraca? Rozumiem, że trzeba wtedy wrócić do PQ i wyczyścić kod M ze wszystkich transformacji na usuniętej kolumnie. Pytanie, czy da się to jakoś automatycznie obsłużyć?
Problemem nie jest sam unpivot, a krok Zmieniono typ w moim zapytaniu Źródło, który trzeba usunąć. Wtedy zapytania działa niezależnie od liczby kolumn do odpivotowania.