


 W poprzednich tekstach dotyczących Power Query omówione zostały omówione najważniejsze przekształcenia danych z zakładki Narzędzia Główne. Oprócz nich mamy także do dyspozycji funkcje z zakładki Przekształć, gdzie znajdziemy możemy znaleźć m. in. Inwersję wierszy, transpozycję, format wyświetlanych liczb i inne. W poniższym tekście analizujemy 3 pierwsze obszary: Tabela, Dowolna Kolumna oraz Kolumna tekstowa.
W poprzednich tekstach dotyczących Power Query omówione zostały omówione najważniejsze przekształcenia danych z zakładki Narzędzia Główne. Oprócz nich mamy także do dyspozycji funkcje z zakładki Przekształć, gdzie znajdziemy możemy znaleźć m. in. Inwersję wierszy, transpozycję, format wyświetlanych liczb i inne. W poniższym tekście analizujemy 3 pierwsze obszary: Tabela, Dowolna Kolumna oraz Kolumna tekstowa.
Obszar ”Tabela”
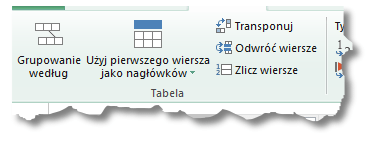
Znajdziemy tutaj następujące przyciski:
– Grupowanie według – przycisk ten znajdzie się także w zakładce Narzędzia Główne. Opis tej funkcjonalności znajduje się w tym artykule.
– Użyj pierwszego wiersza jako nagłówków – opcja ta była już wspomniana w pierwszym tekście dotyczącym Power Query i również znajduje się w zakładce Narzędzia główne. Funkcja ta ma dwa warianty:
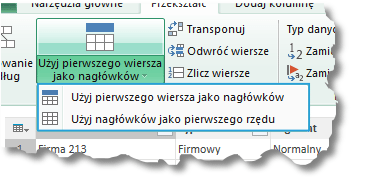
Wariant Użyj pierwszego wiersza jako nagłówków kasuje istniejące nagłówki, w ich miejsce wstawiając wartości z pierwszego wiersza.
Wariant Użyj nagłówków jako pierwszego rzędu powoduje przesunięcie wartości w nagłówkach do pierwszego wersu tabeli. Zamiast starych nazw kolumny otrzymują nagłówki Column1, Column2, Column3 itp.
– Opcja Transponuj powoduje transpozycję tabeli; tj. wiersze stają się kolumnami, a kolumny – wierszami.
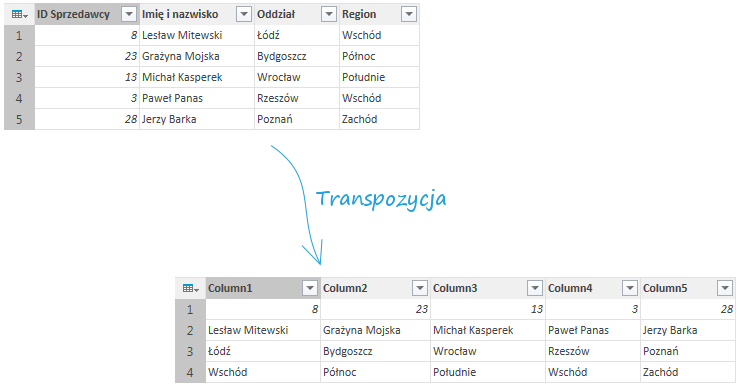
Warto zauważyć iż w wyniku tej operacji zostały stracone nagłówki. Dlatego też powtórne wykonanie transpozycji spowoduje powstanie pierwotnej tabeli bez właściwych nagłówków, ale z nazwami kolumn typu Column1, Column2, Column3 itp.
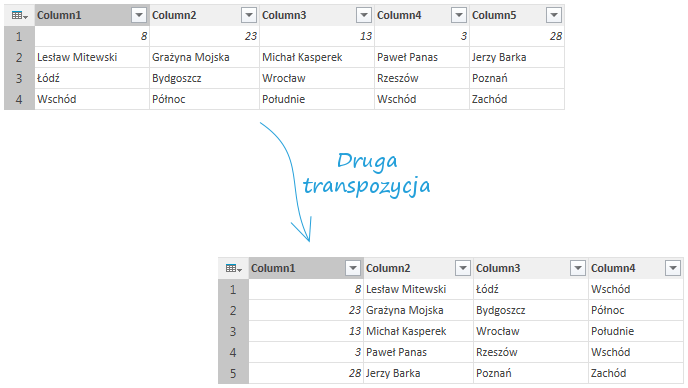
Do pierwotnego stanu najłatwiej wrócić usuwając poszczególne kroki we wstążce Ustawienia zapytania:
– Funkcja Odwróć wiersze powoduje odwrócenie (inwersję) wierszy w tabeli:
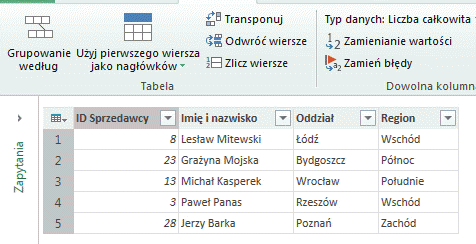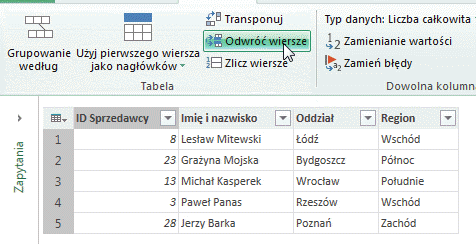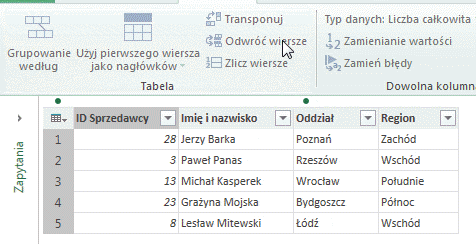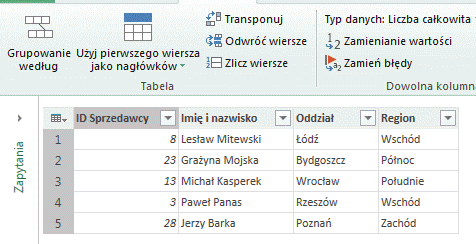
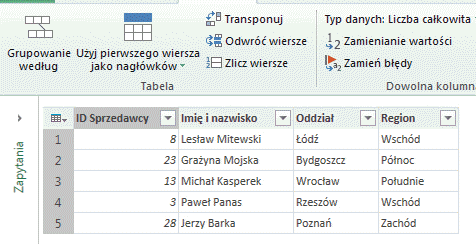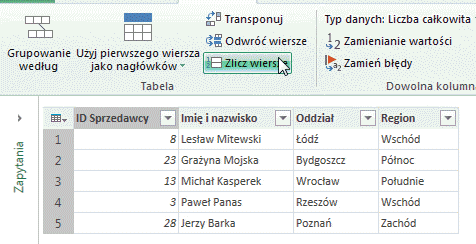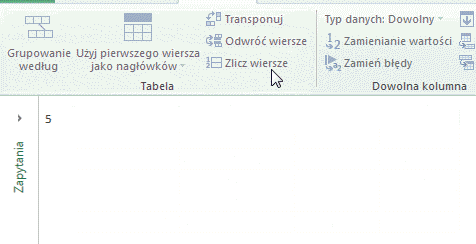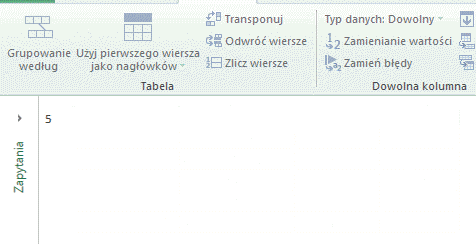
– Przycisk Zlicz wiersze spowoduje wyświetlenie liczby rekordów w tabeli:
 Obszar „Dowolna kolumna”
Obszar „Dowolna kolumna”
Znajdziemy tutaj następujące funkcjonalności:
– Przycisk Typ danych, przy pomocy którego możemy określać typ danych w kolumnie, a co za tym idzie – zmieniać sposób ich wyświetlania. Odpowiednik tej funkcjonalności możemy znaleźć także w zakładce Narzędzia Główne. Szczegółowy opis znajdziemy w trzecim artykule o Power Query.
– Zamienianie wartości, funkcja która jest odpowiednikiem opcji Zamień w Excelu. Opcja ta także jest dostępna z zakładki Narzędzia Główne oraz została opisana w poprzednim tekście.
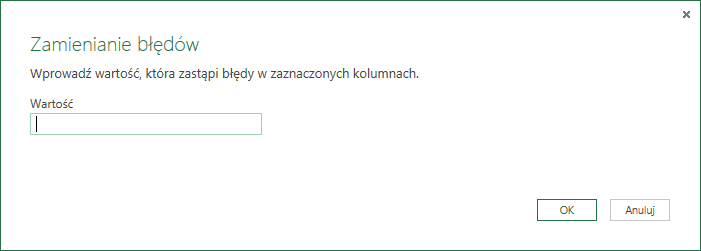
– Funkcja Zamień błędy powoduje zamianę wartości Error na dowolną wartość wybraną przez użytkownika. Wystarczy zaznaczyć odpowiednią kolumnę i wpisać pożądaną wartość w oknie dialogowym które otwiera się po kliknięciu w tą opcję:
Dalej w obszarze tabela mamy zestaw funkcji symbolizowanych przez małe ikony:
– Opcja Wypełnij w dwóch wariantach: wypełnienie w dół oraz w górę.
Jej wykorzystanie powoduje przepisanie do komórki z wartością null wartości znajdującej się nad tą komórką (Wypełnij -> W dół) lub pod tą komórką (Wypełnij -> W górę):
– Opcja Zmień nazwę powoduje zaznaczenie nagłówka kolumny w której aktualnie jest aktywna dowolna komórka. Nazwę kolumny możemy zmienić także klikając prawym przyciskiem myszy na nagłówek i wybierając opcję Zmień nazwę…
– Opcja Kolumna przestawna jest jedną z najbardziej interesujących w danym obszarze.
Przy pomocy tej opcji tworzymy nowe kolumny na podstawie wartości zawartych w początkowo zaznaczonej kolumnie. Co to oznacza w praktyce? Najłatwiej będzie to wytłumaczyć na przykładzie.
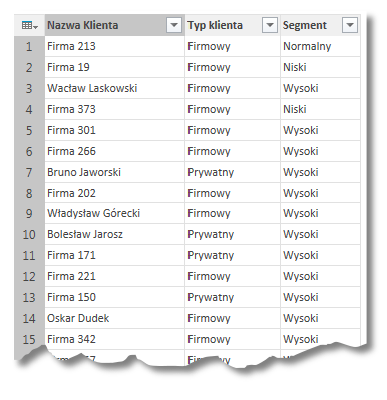
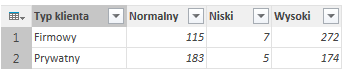
Załóżmy, iż dysponujemy trzykolumnową tabelą klientów naszej firmy. Znajdziemy tam nazwę naszego klienta, jego typ (firma lub osoba prywatna) oraz segment rynku (wysoki, średni lub niski):
Jeżeli przy takiej architekturze tabeli zaznaczymy jakąkolwiek wartość w kolumnie Segment, a następnie wybierzemy opcję Kolumna przestawna to otworzy nam się następujące okno dialogowe:
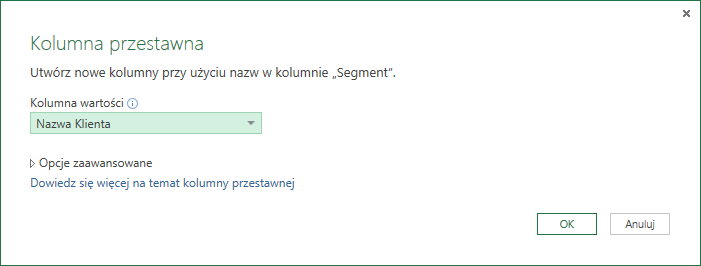
Widzimy, iż nowe kolumny będą miały nagłówki z kolumny Segment, a więc ich nazwy będą brzmiały Wysoki, Średni oraz Niski. Na podstawie pozostałych opcji decydujemy jak wyglądać będzie nasza tabela – w tym celu dobrze jest rozwinąć Opcje zaawansowane (wystarczy kliknąć na ten napis):

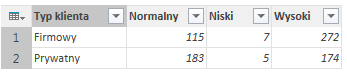
Oprócz powstania nowych kolumn zajdą także inne operacje: zostaną podliczeni klienci należący do poszczególnych segmentów rynku. W związku z tym zniknie kolumna Nazwa klienta, a zamiast niej pojawią się liczbowe pokazujące liczbę klientów należących do wysokiego, średniego bądź też niskiego segmentu.
Nie przeprowadzamy żadnej operacji na kolumnie Typ Klienta – oznacza to, iż pozostaje ona w tabeli a jej zestaw wartości (czyli prywatny oraz firmowy) pozostaje taki sam.
Końcowym efektem jest podział klientów firmy ze względu na ich typ oraz segment:
Jeżeli nasza tabela nie posiadałaby kolumny Typ klienta i składała się jedynie z dwóch kolumn: Nazwy klienta oraz segmentu, to po przeprowadzeniu identycznych co wyżej wspomniane operacji otrzymalibyśmy na końcu jednowierszową tabelę:

Przy korzystaniu z powyższej opcji szczególną uwagę trzeba zwrócić na kolumny zawierające identyfikatory wierszy – niepowtarzalne w całej kolumnie ciągi znaków. Omawiana opcja z wartości jednej kolumny tworzy inne kolumny, z innych kolumn obliczając odpowiednie wartości. Tabela wynikowa nie zmniejszy ilości swoich wierszy jeżeli wartości w kolumnie identyfikującej wiersz są unikalne, a jedynie zwiększy ilość kolumn, a we wszelkie puste miejsca program wstawi wartość null.
Załóżmy, że w identycznej tabeli zawierającej dane na temat nazwy klienta, typu oraz segmentu rynku do którego należy dany klient mamy także ID klienta:
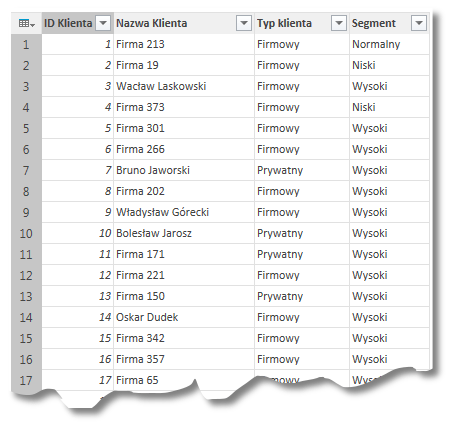
Po wykonaniu dokładnie tej samej operacji co wcześniej, tj. stworzeniu kolumn w oparciu o wartości z kolumny Segment oraz obliczenie liczności po kolumnie Nazwa Klienta otrzymujemy następujący wynik:
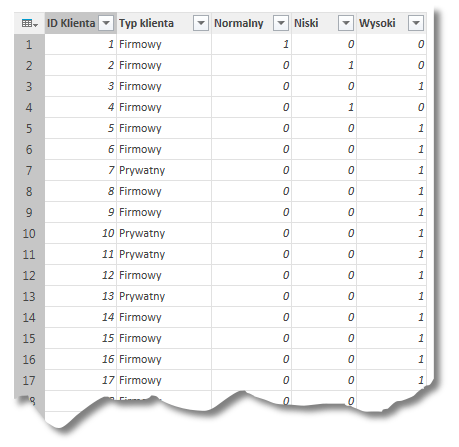
Ponieważ nie są wykonywane żadne operacje na kolumnie ID klienta, to zawiera ona te same wartości co kolumna wejściowa. W efekcie w każdym wierszu w kolumnach Normalny, Niski oraz Wysoki wskazujemy liczbę klientów z przypisanym segmentem, rodzajem oraz numerem ID.
W związku z powyższym opcja Kolumna przestawna przydatna jest raczej w przypadku tabel w których występuje wiele powtórzeń wartości w wierszach.
– Niejaką odwrotność do wyżej opisanej funkcji stanowi opcja Anuluj przestawienie kolumn:
Funkcja ta powoduje zmianę kilku zaznaczonych kolumn w dwie kolumny – atrybutu oraz wartości. Ponownie, działanie najłatwiej będzie przedstawić na konkretnym przykładzie. W tym celu posłużymy się tabelą którą otrzymaną wcześniej wskutek zastosowania opcji Tabela przestawna:
Zaznaczmy kolumny Normalny, Niski oraz Wysoki oraz wybierzmy opcję Anuluj przestawienie kolumn:
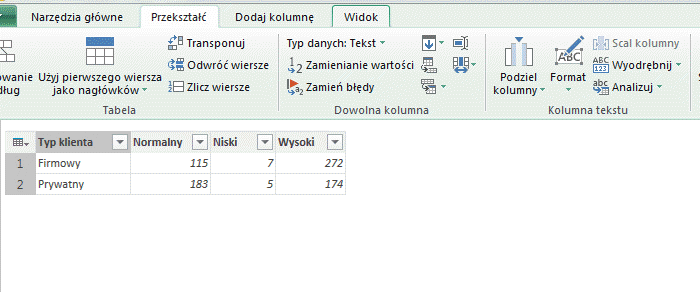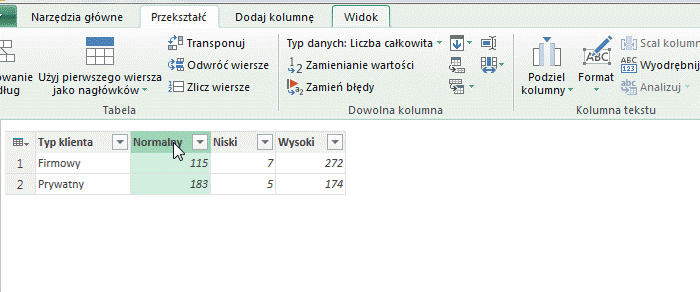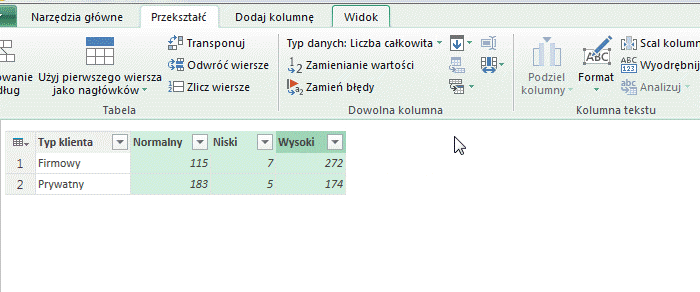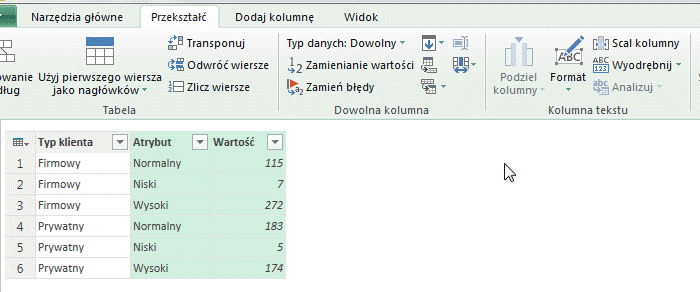
W wyniku operacji otrzymujemy tabelę, w której zamiast zaznaczonych kolumn (w tym przypadku trzech, ale w praktyce może być ich dowolna liczba) otrzymujemy kolumnę atrybutów (z nagłówkami zaznaczonych kolumn) oraz kolumnę wartości (z wartościami z komórek zaznaczonych kolumn):
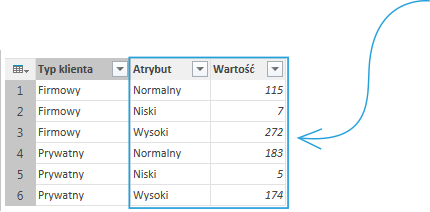
Dokonaliśmy operacji podobnej do translacji – zamieniliśmy wiersze w kolumny, nie zmieniając jednak charakteru kolumn które nie brały udziału w anulowaniu przestawienia kolumn.
Zwróćmy uwagę, iż nie otrzymaliśmy tabeli która była wejściową do funkcji Kolumna przestawna – jeżeli wybierzemy opcję Kolumna przestawna dla tabeli A, a następnie dla wyniku przeprowadzonej operacji wybierzemy anuluj przestawienie kolumn nie otrzymujemy z powrotem tabeli A, lecz inną.
Same nazewnictwo funkcji Kolumna przestawna oraz anuluj przestawienie kolumny wskazywałoby na to, iż przez anulowanie możemy wrócić do stanu wejściowego – jednak byłoby to jedynie dublowanie funkcji, bowiem cofania każdego kroku możemy dokonać we wstążce Ustawienia zapytania:

Takie nazwy wynikają oczywiście z pracy tłumaczy, którzy w tym przypadku prawdopodobnie niestety sami nie zapoznali się z charakterystyką tych funkcji. Trzeba jednak przyznać, że mieli dosyć ciężkie zadanie, ponieważ nazwy omawianych funkcjonalności w oryginale – języku angielskim – to Pivot Column oraz Unpivot column.
Opcja Anuluj przestawienie kolumny ma dwa warianty:
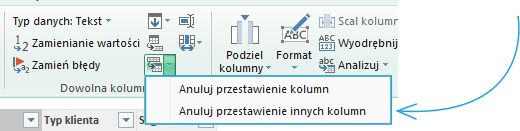
Pierwsza opcja to działanie na zaznaczonych kolumnach – aby funkcja miała sens, należy zaznaczyć więcej niż jedną kolumnę, w przeciwnym przypadku nie zyskamy nic poza dodaniem kolumny w której wszystkie wartości będą wynosiły „Atrybut”. W drugim przypadku – Anuluj przestawienie innych kolumn – zachodzi działanie na wszystkich kolumnach z wyłączeniem tych zaznaczonych przez użytkownika.
– Ostatnia opcja w przestrzeni Dowolna kolumna służy do przesuwania kolumn w dowolną stronę:
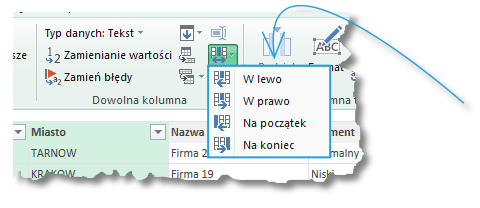
Funkcja ta działa bez zarzutu także w przypadkach zaznaczenia więcej niż jednej kolumny.
Obszar „Kolumna tekstu”
W obszarze tym znajdziemy opcje pozwalające na przekształcanie kolumny w której wartości są tekstem. Będzie to:
– opcja Podziel kolumny, która została opisana już w trzecim tekście o Power Query.
– opcja Format ujawnia swoje prawdziwe funkcje po kliknięciu nań:
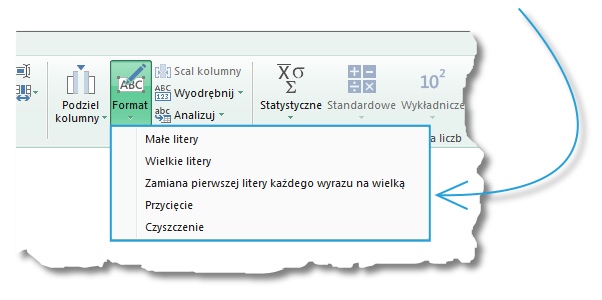
Nazwy funkcji mówią w większości same za siebie. Po kliknięciu Małe litery wszystkie litery w zaznaczonej kolumnie (kolumnach) będą małe – niezależnie od tego, czy występowały tam wartości tekstowe złożone z samych wielkich liter, z małych liter poprzedzonych wielką literą (wtedy następuje ich zmiana na małe) czy też z samych małych liter (wtedy wartość tekstowa w komórce nie ulega zmianie). Analogicznie, funkcja Wielkie litery powoduje pojawienie się samych wielkich liter w interesującej nas kolumnie.
Klikając Zamiana pierwszej litery każdego wyrazu na wielką możemy szybko dokonać edycji wielowyrazowych wyrażeń w komórkach:
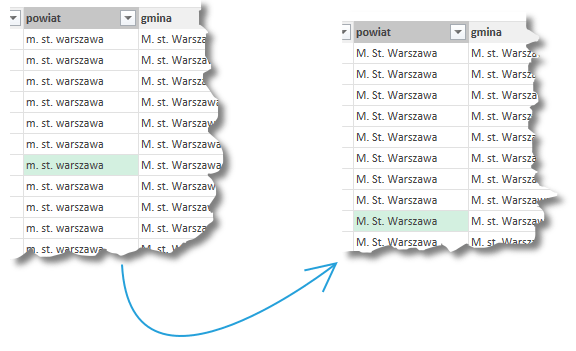
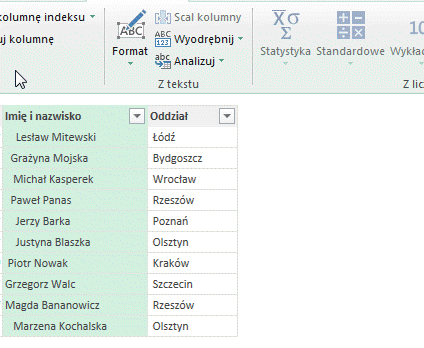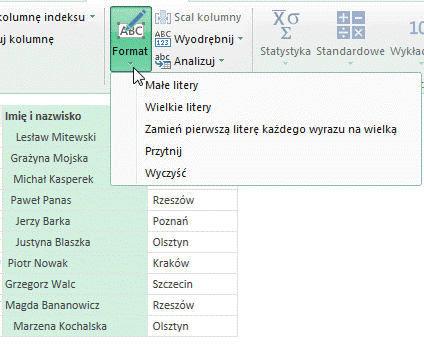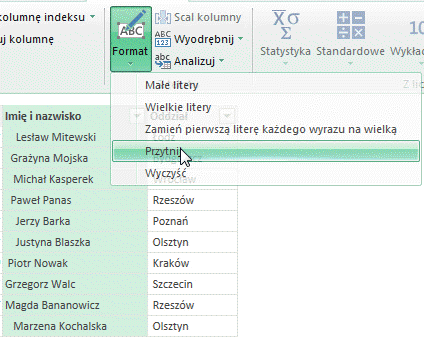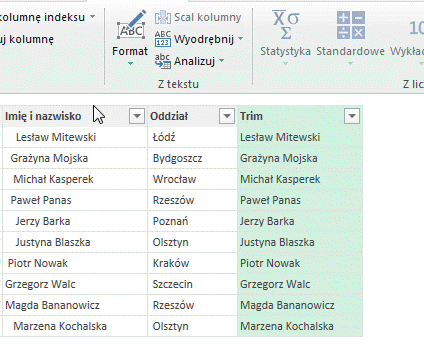
Przycięcie służy do usuwania znaków spacji z początku bądź też z końca wyrażenia. Nie są usuwanie odstępy między wyrazami. Spacje na końcu mogą mieć znaczenie np. podczas łączenia ciągu znaków z dwóch kolumn. W wyniku działania funkcji powstaje nowa kolumna o nazwie Trim.
Przed omówieniem funkcji Czyszczenie należy wyjaśnić pojęcie znaków niedrukowalnych. Są to naturalnie wszystkie znaki, które są widoczne na ekranie komputera podczas edycji tekstu, natomiast nie widać ich w wydruku. Każda osoba pracująca z programem Microsoft Word zapewne zna ten przycisk:

Który ujawnia wszelkie znaki które nie są widocznie ostatecznie na wydruku – symbole spacji, twardej spacji, akapitu, podziału sekcji i tym podobnych.
Oprócz wyżej wspomnianych do znaków niedrukowalnych należy pierwsze 32 znaki w standardzie ASCII.
ASCII to kod przyporządkowujący liczbom od 0 do 127 odpowiednie znaki: litery alfabetu łacińskiego, znaki przestankowe, symbole, a także znaki niedrukowalne, które w tym kodzie zajmują pierwsze 32 miejsca. Z czasem tak mała liczba znaków przestała działać, dlatego też wprowadzono standard UNICODE zawierający znacznie większą (i wciąż powiększającą się) liczbę znaków. Pierwsze 128 znaków w standardzie UNICODE to znaki z ASCII.
Dowolny znak z powyższych standardów możemy napisać przytrzymując lewy ALT i wpisując numer znaku na klawiaturze numerycznej. Tabelę znaków ASCII możemy znaleźć w wielu miejscach w sieci, wliczając w to Wikipedię.
Wstawianie tych znaków w Excelu odbywa się poprzez funkcję ZNAK lub ZNAK UNICODE. W poniższej tabeli znaki niedrukowalne zostały umieszczone przed i po imieniu i nazwisku sprzedawców:
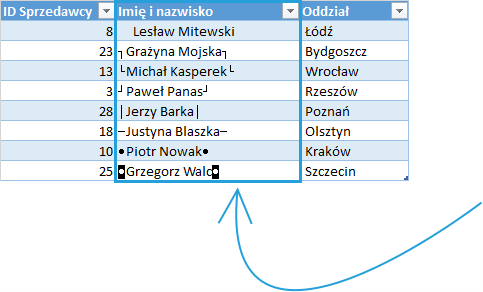
Po załadowaniu powyższej tabeli do edytora Power Query znaki nie są wyświetlane; nie znaczy to jednak, że znikają, bowiem po kliknięciu w edytorze Załaduj i zamknij (bez znaczenia jest to, czy dokonywaliśmy na tabeli jakichkolwiek operacji)i otworzeniu tej tabeli w arkuszu Excela znowu pojawiają się znaki niedrukowalne. Zastosowanie funkcji Czyszczenie pozornie nie zmienia niczego w tabeli znajdującej się w edytorze PowerQuery, jednakże po załadowaniu tabeli na której zastosowaliśmy tą opcję widzimy, iż usunęliśmy wyżej wspominane znaki.
Funkcja usuwania znaków niedrukowalnych nie jest w Excelu niczym nowym – wcześniej mogliśmy użyć do tego celu formuły OCZYŚĆ, która działa w podobny sposób.
Przycisk Scal kolumny aktywuje się jedynie w przypadkach zaznaczenia więcej niż jednej kolumny.
Przy pomocy tej funkcjonalności możemy połączyć kilka kolumn w jedną. Miłą opcją jest możliwość rozdzielenia wartości z poszczególnych kolumn dowolnym znakiem, co zwalnia użytkownika z kombinowania (np. tworzenia kolumny z samym spacjami bądź przecinkami):
Możemy także zdefiniować własny, niestandardowy separator.
Następna opcja w obszarze Kolumna tekstowa to Wyodrębnij, która posiada kilka wariantów: Długość, Pierwsze znaki, Ostatnie znaki, Zakres:
Funkcja Wyodrębnij długość zamienia ciąg znaków na liczbę określającą długość tego ciągu w poszczególnych komórkach w zaznaczonej kolumnie. Jest to odpowiednik funkcji DŁ ze skoroszytu Excela.
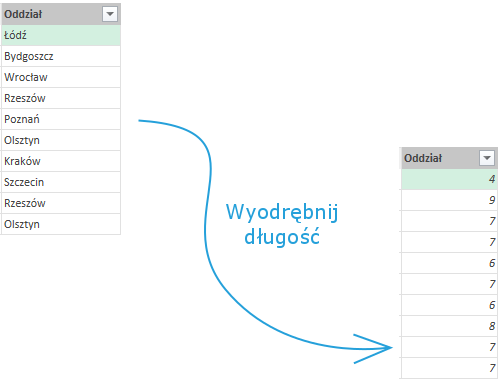
Wariant Wyodrębnij > Pierwsze znaki działa na tej samej zasadzie co funkcja LEWY – zwraca określoną przez użytkownika liczbę znaków licząc od początku, czyli od lewej strony. Inaczej mówiąc – skraca ciąg do pożądanej długości.
Analogiczne działanie ma opcja Ostatnie znaki, z tą różnicą, iż skracanie odbywa się z prawej strony ciągu.
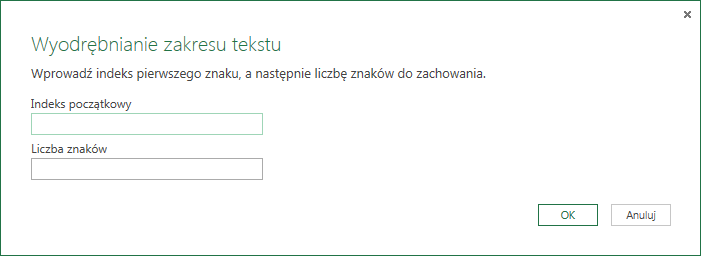
Zakres jest odpowiednikiem funkcji FRAGMENT.TEKSTU. Przy pomocy tej funkcjonalności skracamy ciąg znaków określając pozycję znaku początkowego i końcowego z ciągu wejściowego:
Ostatnia opcja w obszarze Kolumna tekstu to przycisk Analizuj, który ma w sobie dwie opcje: Kod XML oraz JSON:
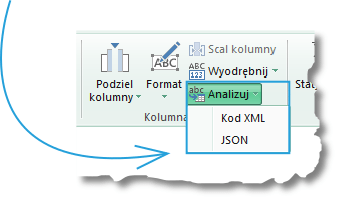
Wbrew pozorom opcje te nie polegają na analizie danych pobranych z plików XML bądź też JSON. Zgodnie z nazwą obszaru – Kolumna tekstowa – pracujemy na tekście znajdującym się w komórkach kolumny, który może być kodem XML bądź JSON.
Analiza oznacza rozkład na czynniki, i to też robimy przy pomocy tej opcji. Z tekstu zapisanego w jednej kolumnie wyodrębniamy kilka kolumn poprzez analizę – czyli rozłożenie na czynniki – kodu.
Kod XML to bardzo prosty i uniwersalny język znaczników. Przykładowa linijka tego kodu wygląda w następujący sposób (dla ułatwienia oznaczymy znaczniki kolorami):
<sprzedawcy><id_sprzedawcy>8</id_sprzedawcy><imie_i_nazwisko>Lesław Mitewski</imie_i_nazwisko><oddział>Łódź</oddział></sprzedawcy>
Elementy takie jak ID sprzedawcy, imię i nazwisko oraz oddział są oznaczone znacznikami. Pomiędzy nimi znajdują się konkretne dane w postaci węzłów tekstowych. Element „sprzedawcy” jest rodzicem w odniesieniu do pozostałych elementów. Może wystąpić więcej poziomów elementów, tzn. inne elementy mogą być rodzicem dla elementu sprzedawcy, który z kolei jest rodzicem dla innych elementów.
Działanie omawianej funkcji zostanie przedstawione na poniższej tabeli:
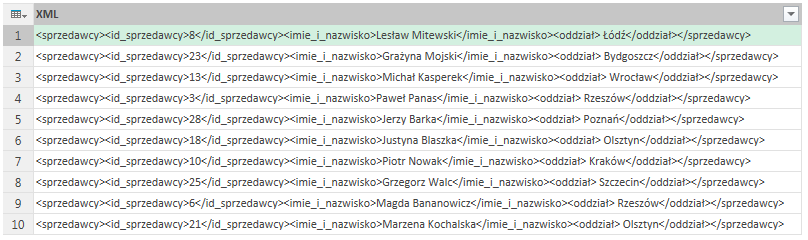
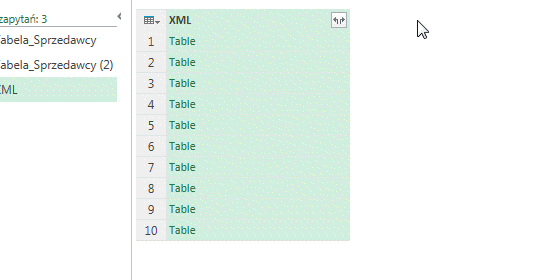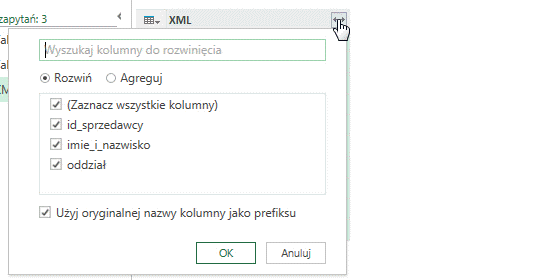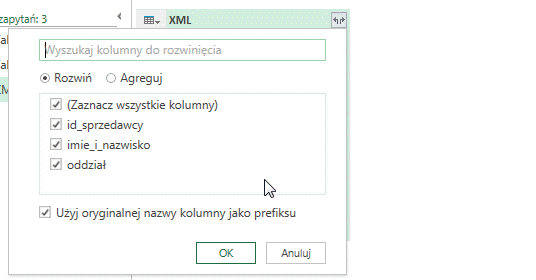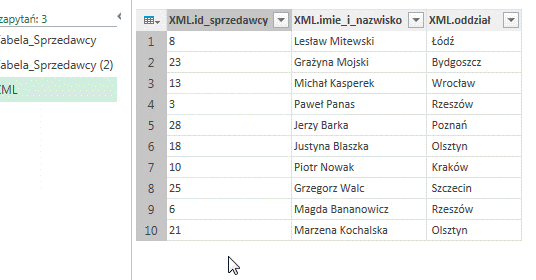
Znajdują się w niej dane dotyczące kilku sprzedawców zapisane przy pomocy formatu XML. Po zaznaczeniu kolumny i kliknięciu Analizuj -> Kod XML otrzymujemy następującą kolumnę:
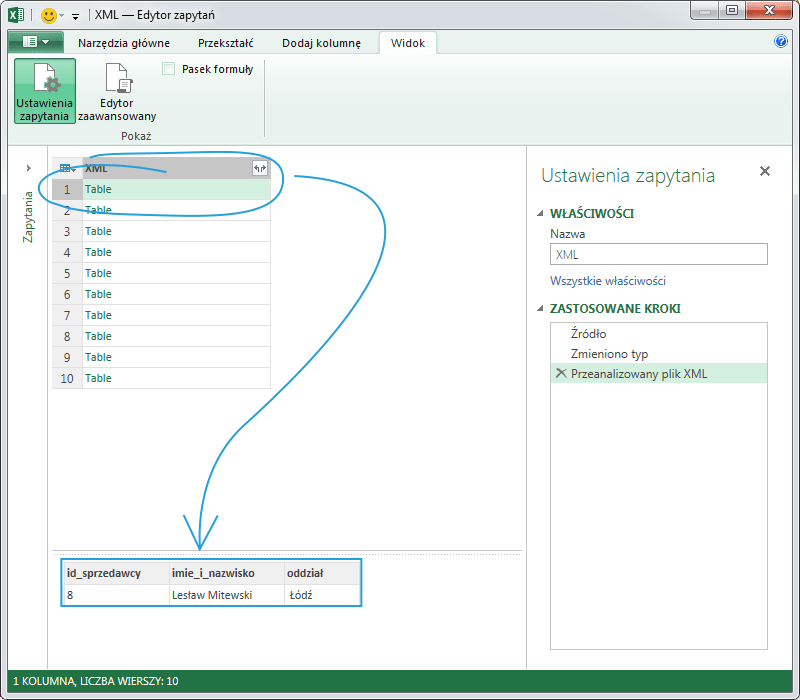
Zaznaczenie dowolnej komórki z wartością Table spowoduje wyświetlenie wartości tej tabeli w obszarze znajdującym się w dolnej części okna Power Query:
Rozwinąć wszystkie wiersze i stworzyć tabelę możemy poprzez kliknięcie w symbol strzałek znajdujący się w nagłówku kolumny, wybranie opcji Rozwiń a następnie OK:
Bardzo podobnie przedstawia się zagadnienie analizy zapisu JSON, dlatego też w tym tekście nie będziemy omawiać tego przypadku.
Narzędzie Analiza nie ma swojego odpowiednika ani w zwykłych funkcjach Excela, ani też w PowerPivot. Może stanowić ciekawą alternatywę w stosunku do pobierania całych plików XML, pełnić funkcję edukacyjną poprzez umożliwienie zrozumienia działania analizowanych form zapisu, czy też stanowić narzędzie analizy plików coraz popularniejszego standardu XML, w którym dane udostępnia m. in. Centralny Ośrodek Dokumentacji Geodezyjnej i Kartograficznej czy też niektóre dane z Głównego Urzędu Statystycznego (np. rejestr TERYT).
Co sądzicie o powyższych metodach przekształcania danych? Czy funkcja analizy może okazać się przydatna? Podzielcie się swoim zdaniem w komentarzach.




Witam. Mam pewien problem, cyklicznie pobieram dane z internetu i probuje probuje automatycznie przeksztalcac je za pomoca PQ niestety excel widzi je jako potencjalnie niebezpiecznie i dopiero po otwarciu i odblokowaniu zawartosci PQ ma do nich dostep. Czy jest sposob aby to naprawic?
Ps super artykul
Są 2 opcje sterowania zawartością:
1. Z poziomu Excela możesz w Centrum Zaufania (Plik > Opcje > Centrum zaufania > Zawartość zewnętrzna) wymusić brak pytania o włączenie zawartości.
2. W samym Power Query możesz ustawić Poziom prywatności dla źródła danych (np. wyłączyć prywatność dla konkretnej strony).
Cześć,
Na samym początku chciałbym zaznaczyć ze jest to bardzo przydatny poradnik jak stworzyć taka funkcjonalność w PowerQuery. Natomiast nie potrafię stworzyć dwóch parametrów ponieważ wybija mi jakiś błąd, domyślam się ze to dlatego ze mam gdzieś te same nazwy. Bardzo proszę o pomoc lub o podanie jak dodać więcej parametrów które będę mógł dodać jako zmienne w PowerQuery w edytorze zaawansowanym po komendzie „Let”
Hej Paweł, zmienne podajesz przed słowem „let”, deklarując je w nawiasie wraz z typem danych, np.:
(test as number, test2 as text) =>