
 Kiedy już zaimportowaliśmy odpowiednie dane do Power Query i przy pomocy funkcji Scal oraz Dołącz otrzymaliśmy tabele zawierające potrzebne nam dane, możemy zacząć je przekształcać. Jednym z podstawowych działań pozwalających na uzyskanie nowej informacji jest grupowanie wierszy tabeli. Dodatkowo możemy zmieniać dane np. poprzez dzielenie kolumny.
Kiedy już zaimportowaliśmy odpowiednie dane do Power Query i przy pomocy funkcji Scal oraz Dołącz otrzymaliśmy tabele zawierające potrzebne nam dane, możemy zacząć je przekształcać. Jednym z podstawowych działań pozwalających na uzyskanie nowej informacji jest grupowanie wierszy tabeli. Dodatkowo możemy zmieniać dane np. poprzez dzielenie kolumny.
Grupowanie
Należy nadmienić, iż w Excelu termin grupowanie nie jest niestety jednoznaczny. Oprócz obróbki danych, która jest przedmiotem tego artykułu, pod tą samą nazwą kryje się sposób zarządzania widocznością kolumn oraz wierszy. Mowa tutaj o opcjach dostępnych w obszarze Konspekt:

Te przyciski służą do nadawania kolumnom bądź wierszom struktury rozwijanego drzewa, nieco podobnej do tej jaką możemy przy odpowiednich ustawieniach uzyskać w tabeli przestawnej. Wystarczy zaznaczyć kilka wierszy bądź kolumn i nacisnąć Grupuj, aby pojawiły się przyciski pozwalające chować i rozwijać zaznaczony obszar. Warto zaznaczyć, iż można tworzyć „grupę w grupie”:
Nieco inna funkcjonalność pod tą samą nazwą kryje się w Power Query w zakładce Narzędzia główne w obszarze Przekształć:
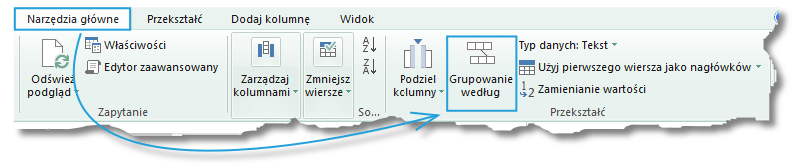
Opcja Grupowanie według pełni funkcję analogiczną do komendy GROUP ON w języku SQL – pozwala na agregację wierszy poprzez wykonanie odpowiedniej operacji. W efekcie grupowania otrzymujemy mniejszą od pierwotnej tabelę zawierającą przetworzone dane, w wyniku czego możemy otrzymać nową informację.
Najłatwiej działanie grupowania wyjaśnić na przykładzie. Załóżmy, iż nasza firma zajmuje się sprzedażą dóbr, a my mamy dostęp do danych dotyczących każdej transakcji – między nimi do tego, który sprzedawca ją przeprowadził.
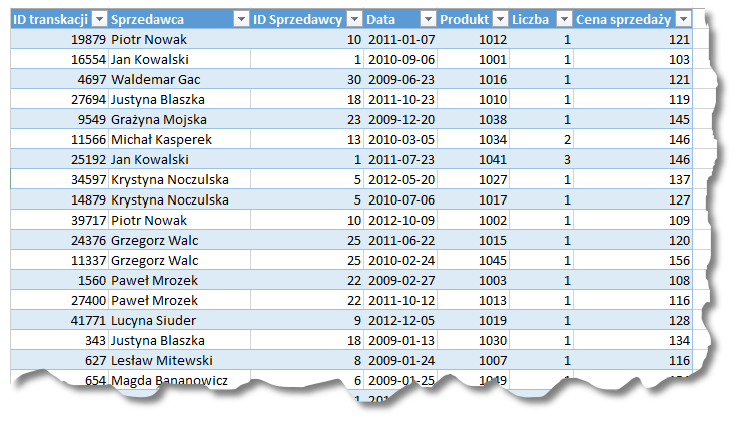
Mając takie dane, możemy przeprowadzić grupowanie po sprzedawcy – ilość wierszy przypadająca na danego handlarza w prosty sposób przekłada się na ilość wykonanych transakcji.
W celu przeprowadzenia operacji grupowania musimy załadować tabelę do edytora zapytań (o imporcie danych do edytora pisaliśmy w części 1), po czym naturalnie klikamy Grupuj według. Otworzy nam się okno Grupowanie według:
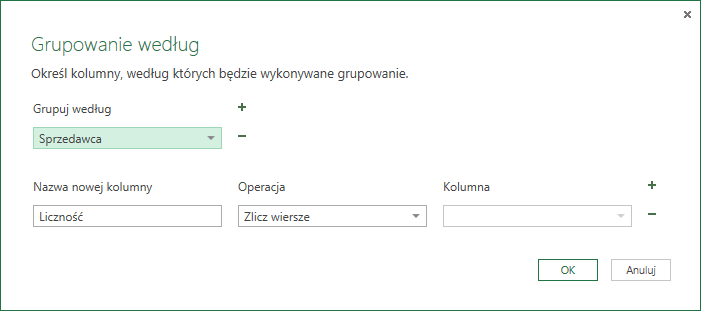
Wybieramy grupowanie po kolumnie Sprzedawca oraz operację zliczenia wierszy aby otrzymać interesujący nas wynik:
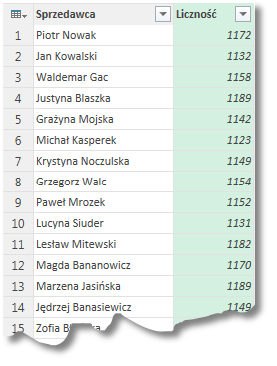
Warto zauważyć, iż grupowanie możemy przeprowadzać na więcej niż jednej kolumnie; klikniecie w symbol plusa znajdujący się obok napisu Grupuj według doda okno w którym możemy wskazać jeszcze jedną kolumnę; analogicznie kliknięcie minusa obok okienka z kolumną grupowania powoduje jej usunięcie.
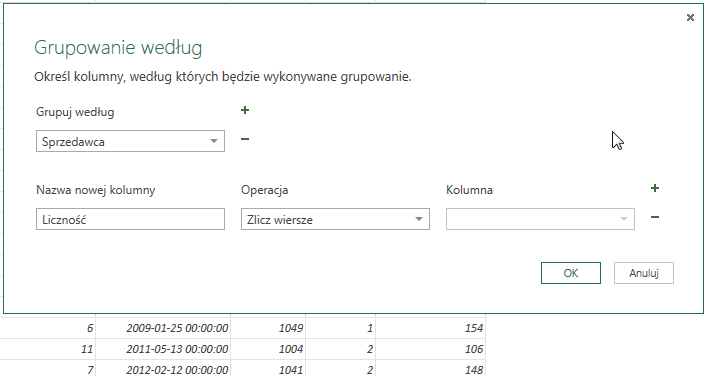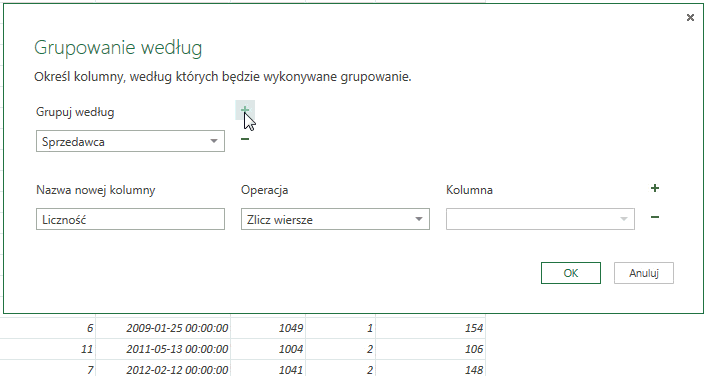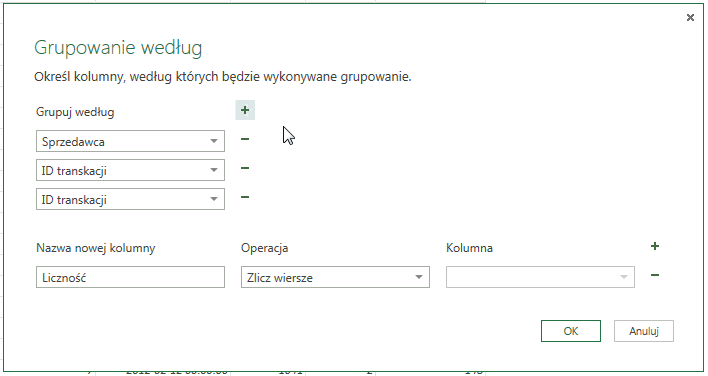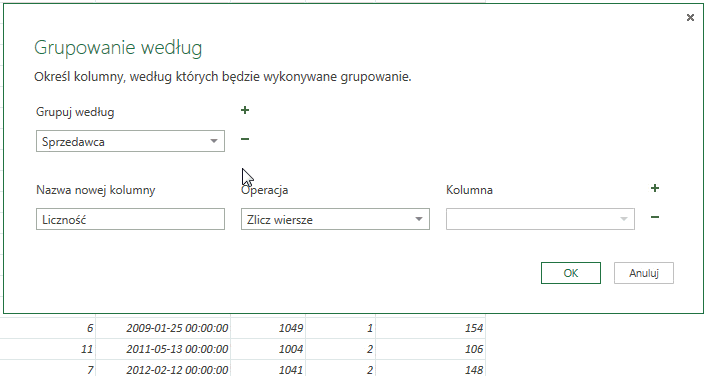
W ten sposób możemy na przykład sprawdzić ile produktów danego typu sprzedał konkretny sprzedawca – wystarczy pogrupować wg ich nazwiska oraz kategorii sprzedanego dobra.
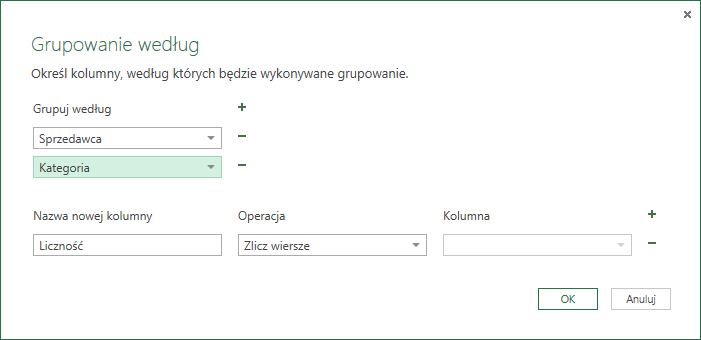
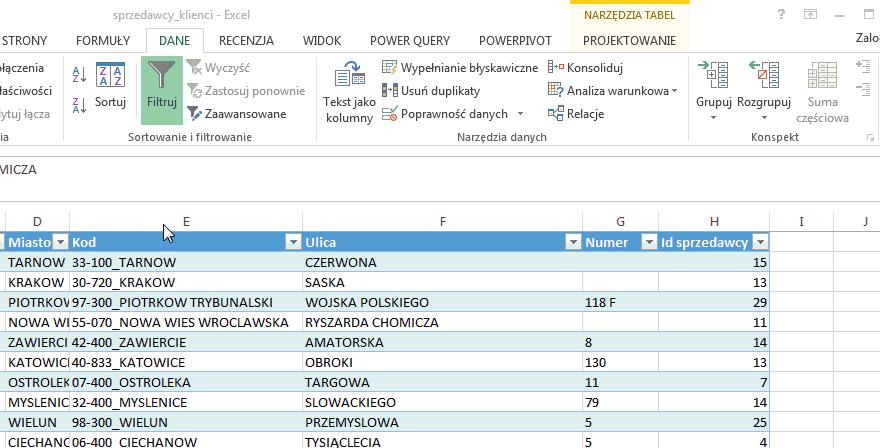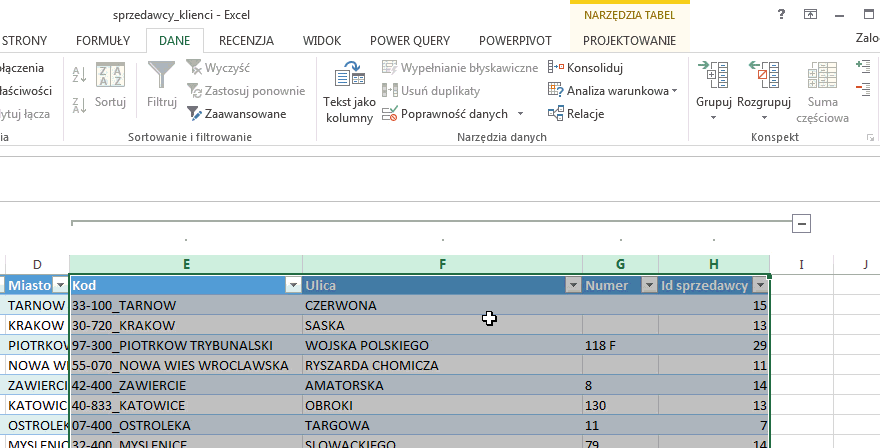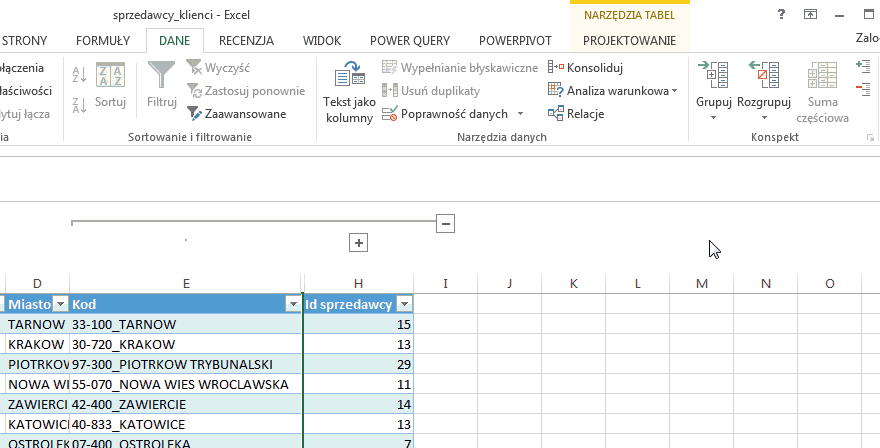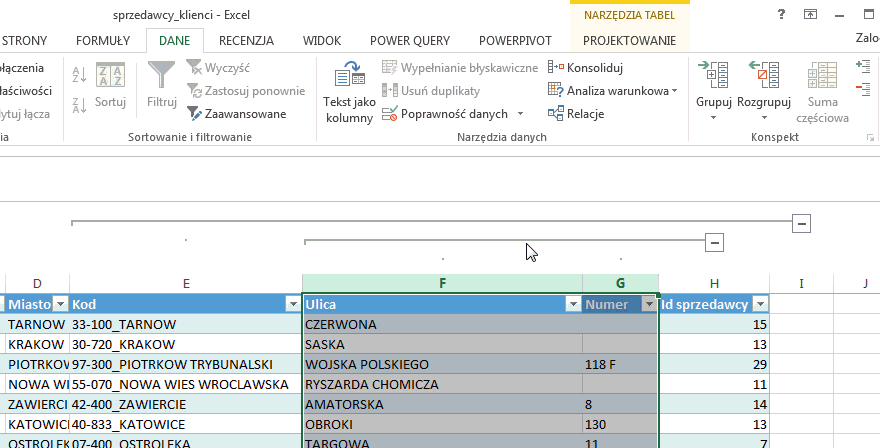
W efekcie otrzymamy następującą tabelę:
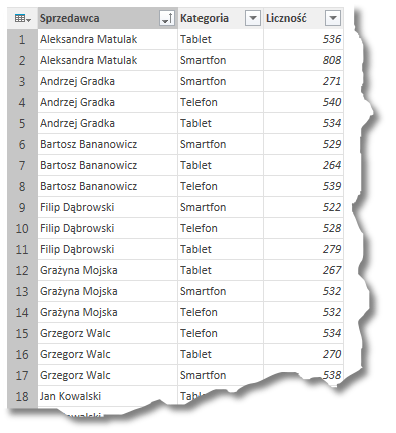
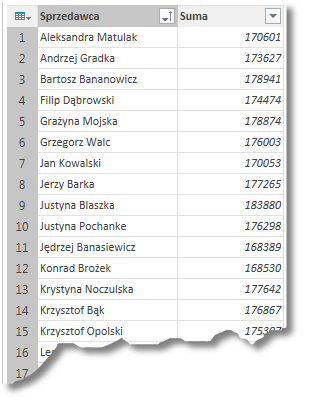
Oprócz zliczania kolumn możemy wykonywać także inne działania: możemy na przykład sumować cenę produktów, w wyniku czego otrzymamy informację jaki przychód wygenerował konkretny sprzedawca. W takim przypadku musimy wskazać, na jakiej kolumnie wykonujemy naszą operację (w tym przypadku – sumowanie):
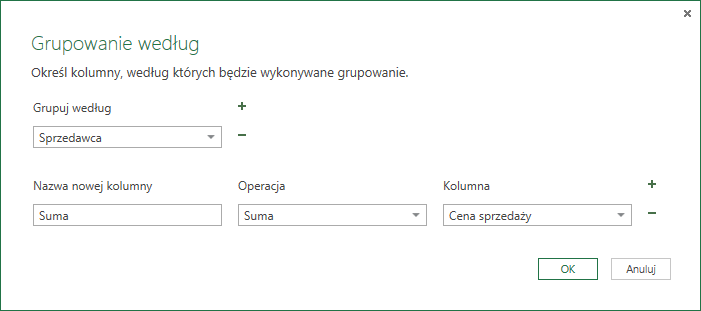
W efekcie otrzymujemy listę sprzedawców wraz z wygenerowanym przez nich przychodem:
Istnieje także możliwość przeprowadzenia większej ilości operacji grupowania – zarówno na jednej, jak i na wielu kolumnach. Oznacza to, iż np. możemy zsumować cenę wszystkich sprzedanych produktów przez danego sprzedawcę, a także obliczyć średnią cenę sprzedaży – wykonujemy dwa działania na jednej kolumnie. Można także zsumować liczbę sprzedanych urządzeń oraz wyliczyć średnią cenę sprzedaży – w takim wypadku wykonujemy dwa działania na dwóch różnych kolumnach.
Aby wykonać działanie na więcej niż jednej kolumnie należy kliknąć w symbol plusa znajdujący się obok napisu:
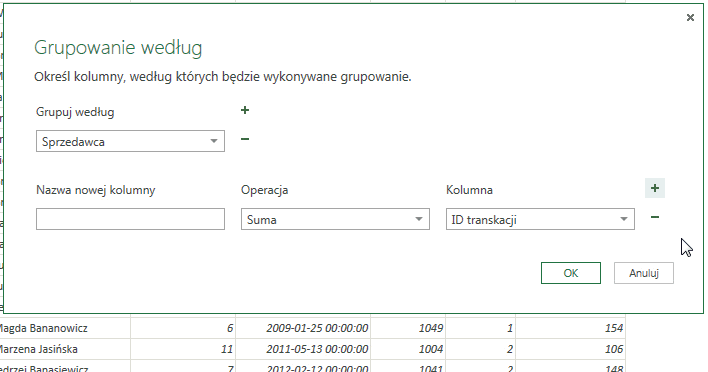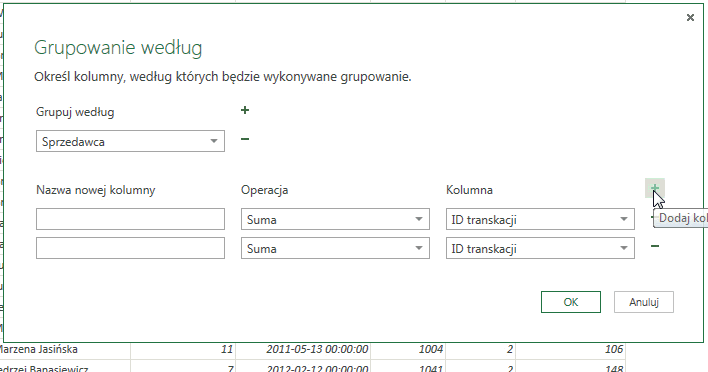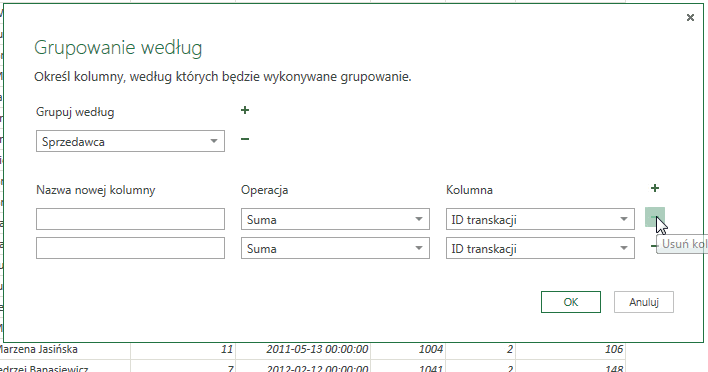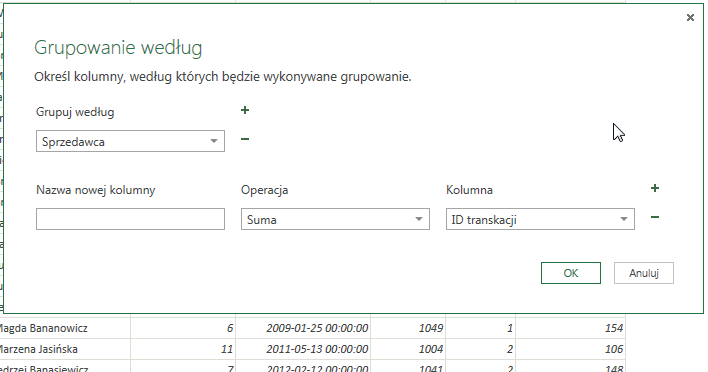
Na podstawie podejmowanych przez nas działań możemy podzielić tabelę wejściową (przed grupowaniem) na sekcję grupowania oraz sekcję danych surowych (ang. raw data). Sekcja grupowania jest zakresem komórek wyznaczonych przez kolumny według których przeprowadzane jest grupowanie oraz składająca się z wierszy które w obszarze tych kolumn mają takie same wartości. Sekcja danych surowych zaś to pozostałe kolumny przypadające na sekcję grupowania.
Najłatwiej wyjaśnić to na przykładzie – załóżmy, iż przeprowadzamy grupowanie po nazwisku sprzedawcy oraz kategorii produktu jaki sprzedał, ale poza tymi dwoma informacjami w tabeli mamy także inne dane – cena produktu, id klienta i tak dalej. W takim przypadku sekcje będą wyglądać w następujący sposób:
Jeżeli chcemy wiedzieć jakie linijki kodu kryją się za poszczególnymi funkcjami Power Query, możemy użyć funkcji Edytor zaawansowany (o którym pisaliśmy już w drugiej części). Kod który tam znajdziemy możemy poddać analizie, porównując ją z wykonanymi przez nas krokami, które znajdziemy we wstążce Ustawienia zapytania. Na tej podstawie możemy wywnioskować, iż komenda odpowiedzialna za grupowanie to Table.Group. Przykładowa kwerenda wygląda w następujący sposób:
#”Pogrupowano wiersze” = Table.Group(Źródło,{„Sprzedawca”, „Producent”}, {{„Liczność”, each Table.RowCount(_), type number}, {„srednia”, each List.Average([Cena]), type number}})
Pierwszym argumentem komendy Table.Group jest tabela którą przekształcamy – w tym wypadku oznaczona tekstem Źródło (jest to domyślna nazwa po imporcie tabeli z dowolnego źródła). Następnie mamy nazwy kolumn należących do sekcji grupującej, czyli takich na podstawie których wykonujemy grupowanie (Sprzedawca oraz Producent), po czym występuje nawias w którym określone są parametry nowopowstałych w wyniku grupowania kolumn:
{{„Liczność”, each Table.RowCount(_), type number}, {„srednia”, each List.Average([Cena]), type number}}
Powstanie kolumna Liczność w której będzie zliczana ilość wierszy przypadająca na dany zestaw wartości w sekcji grupującej (funkcja Table.RowCount ze stałym argumentem (_)) oraz kolumna srednia w której będzie można znaleźć średnią wyciągniętą z kolumny Cena tabeli wejściowej(funkcja List.Average z kolumną [Cena] jako argumentem). Obie te kolumny będą zawierały liczbowy typ danych, o czym informuje komenda type number.
Grupowanie można wykonać też w inny sposób, w skoroszycie Excela – można wykorzystać stare dobre tabele przestawne, które wciąż pozostają jednym z najbardziej uniwersalnych narzędzi.
Dzielenie kolumn
Oprócz funkcji grupowania w obszarze Przekształć możemy znaleźć funkcję Podziel kolumny. Po kliknięciu w nią okazuje się, iż kolumny możemy dzielić na dwa sposoby – według ogranicznika (dowolny znak – np. średnik) lub też według liczby znaków.
Jeżeli zdecydujemy się na podział kolumny według ogranicznika, to otworzy nam się następujące okienko:
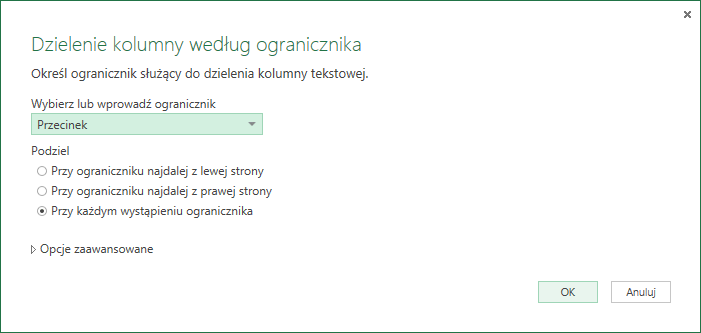
Możemy w nim wskazać jaki znak ma oznaczać miejsce podziału kolumny oraz sposób podziału.
Opcja dzielenia Przy ograniczniku najdalej z lewej strony oznacza, iż program będzie brał pod uwagę pierwszy symbol ogranicznika. Przykładowo, jeżeli w kolumnie będziemy mieli tekst:
Jan Kowalski, Sprzedawca, Wrocław
To po podzieleniu przy zaznaczonej omawianej opcji otrzymamy dwie kolumny: w jednej z nich będzie znajdował się tekst <Jan Kowalski>, natomiast w drugiej będzie znajdować się pozostała część: <Sprzedawca, Wrocław>. Warto zwrócić uwagę, iż ogranicznik w miejscu podziału kolumny znika – w przytoczonym przykładzie znika przecinek po nazwisku.
Analogicznie sprawa się ma z opcją „Przy ograniczaniu najdalej z prawej strony” – wtedy otrzymalibyśmy kolumny <Jan Kowalski, Sprzedawca> oraz <Wrocław>. Trzeba przyznać, iż konstrukcja stylistyczna tych opcji nie jest najszczęśliwsza – można by to było zastąpić na przykład wyrażeniami Przy pierwszym ograniczniku oraz przy ostatnim ograniczniku. Nie dla wszystkich może być jasne co oznacza najdalej z lewej strony – można to interpretować jako ogranicznik najbliższy lewemu końcowi tekstu, jak i jako ogranicznik najdalszy lewej stronie, czyli ostatni.
Po zaznaczeniu opcji dzielenia Przy każdym wystąpieniu ogranicznika pojawia się opcja wyświetlenia opcji zaawansowanych:

Wartość Liczba kolumn na którą zostanie podzielona kolumna zmienia się automatycznie w zależności od zawartości kolumny – domyślna jest wartość która jest liczbą ograniczników w komórce gdzie jest ich najwięcej. W kolumnach gdzie jest mniej ograniczników niż kolumn będących wynikiem podziału komórki zostaną wypełnione wartością null. Poniżej przykład podziału na 4 kolumny:
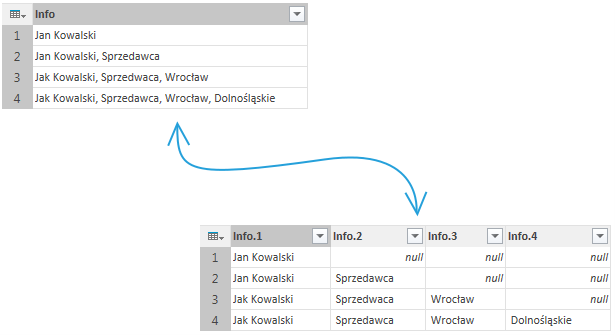
Oprócz dzielenia przy pomocy ograniczników istnieje także możliwość podziału kolumn na podstawie liczby znaków. Po wyborze opcji Podziel kolumny > Według liczby znaków otworzy nam się okno, w którym możemy zdefiniować po którym znaku ma nastąpić podział kolumny i od której strony będzie następowało liczenie:

Wynikiem operacji przy zaznaczonej opcji pierwszej lub drugiej będą dwie kolumny z podzielonym na dwie części ciągiem tekstowym. W przypadku wybrania opcji Powtarzalne mamy do wyboru opcje zaawansowane:
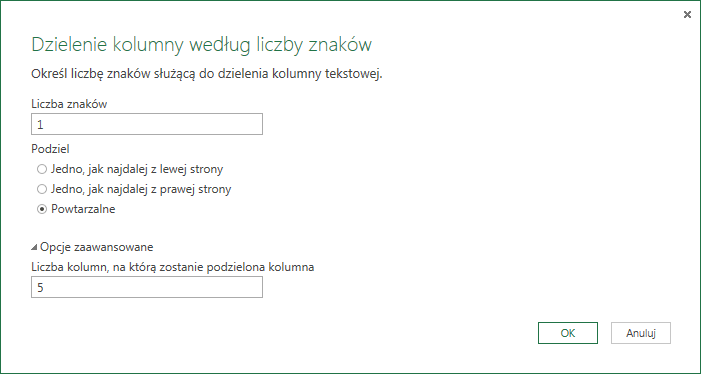
Skutkiem wybrania tej opcji będzie utworzenie podzielenie kolumny na wiele kolumn (w przeciwieństwie do poprzednich wariantów jest możliwość utworzenia więcej niż dwie kolumny). Program podzieli ciąg znaków w kolumnie co określoną liczbę znaków i utworzy zadaną ilość kolumn. Domyślnie wartość pojawiająca się w polu Liczba kolumn, na którą zostanie podzielona kolumna będzie wystarczająco wysoka aby nie pominąć żadnego znaku z kolumny początkowej. Oczywiście mamy możliwość ręcznie zmniejszyć ten parametr (w takim wypadku pominięte zostaną znaki z prawej strony ciągu tekstowego, które się nie zmieszczą). Jeżeli komórka zawiera niedostateczną liczbę znaków to po podziale puste komórki otrzymają wartość null.
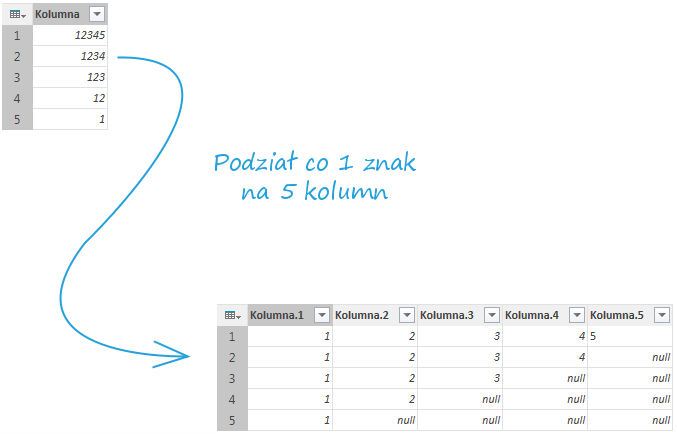
Po wypróbowaniu funkcji podziału, podobnie jak w przypadku grupowania, warto zapoznać się z kodem w edytorze zaawansowanym. Możemy w nim zauważyć, że za każdy sposób dzielenia kolumny) odpowiada komenda Table.SplitColumn. Argumentami tej formuły są kolejno tabela w której znajduje się dzielona kolumna, nazwa tej kolumny oraz argument określający sposób podziału:
- SplitTextByDelimiter(„_”, QuoteStyle.Csv),{„Kod.1”, „Kod.2”}) oznacza podział przy każdym wystąpieniu ogranicznika; w w pierwszym nawiasie zawarty jest ogranicznik (symbol „_”), styl cytatu, w drugim natomiast znajdują się nazwy tworzonych kolumn. Standardowo na taką nazwę składa się tytuł kolumny dzielonej, kropka oraz liczba porządkowa.
- SplitTextByEachDelimiter({„-„}, QuoteStyle.Csv, true),{„Kod.1”, „Kod.2”}) oznacza podział przy pomocy pierwszego ogranicznika z lewej strony – określa to trzeci argument w pierwszym nawiasie, czyli wartość true. Dla podziału przy pomocy pierwszego ogranicznika z prawej strony wartość ta będzie wynosiła false. Pozostałe oznaczenia są takie same jak w poprzedniej opcji.
- SplitTextByRepeatedLengths(4),{„Kod.1”, „Kod.2”, „Kod.3”}), oznacza podział kolumny dokonujący się co 3 znaki licząc od lewej strony. Drugi akapit definiuje nazwy oraz liczbę nowopowstałych kolumn. W tym wypadku kolumna dzieli się co cztery znaki i zostają utworzone trzy kolumny.
- SplitTextByPositions({0, 6}, false),{„Kod.1”, „Kod.2”}), Oznacza podział kolumny na dwie, z czego pierwsza składa się z 6 liter ciągu znaków kolumny dzielonej licząc od lewej, a druga składa się z pozostałych znaków. O stronie od której się liczbę znaków decyduje wartość logiczna – w przypadku false liczymy od lewej, true – od prawej.
Przykładowa komenda podziału może wyglądać w następujący sposób:
#”Podzielono kolumnę według położenia” = Table.SplitColumn(#”Zmieniono typ”,”Kod”,Splitter.SplitTextByPositions({0, 6}, false),{„Kod.1”, „Kod.2”}),
Napis #”Zmieniono typ” oznacza tabelę będącą wynikiem poprzedniej akcji. Bezpośrednio przed wykonaniem podziału kolumny program zmienia jej typ na tekstowy. „Kod” jest nazwą dzielonej kolumny, Splitter.SplitTextByPositions({0,6}, false) oznacza podział kolumny po 6 znaku licząc od lewej, a nawias {„Kod.1”, „Kod.2”} zawiera w sobie nazwy nowych kolumn.
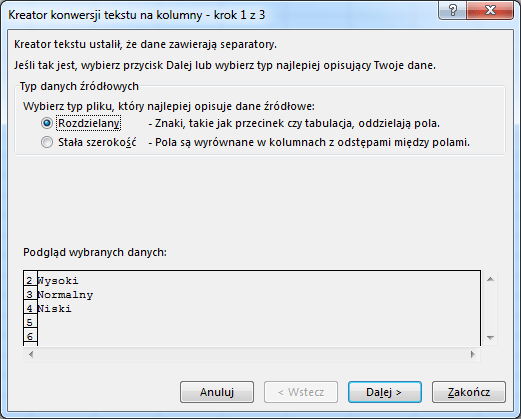
Analogiczny efekt podziału można uzyskać w skoroszycie Excela przy pomocy funkcji LEWY lub PRAWY bądź też w dodatku PowerPivot przy pomocy formuł języka Data Analysis Expressions LEFT lub RIGHT. Inną drogą do do podziału komórek jest zastosowanie opcji Tekst jako kolumny z obszaru Narzędzia danych w zakładce DANE:
Po wybraniu tej opcji pojawi się okno dialogowe dobrze nam znane choćby z importu tekstu, gdzie w podobny sposób musimy wskazać jak podzielić wiersz tekstu na poszczególne komórki.
Widzimy więc, iż efekt funkcji Podziel kolumnę z PowerQuery możemy uzyskać także innymi sposobami.
Typy danych oraz zamienianie wartości
Oprócz funkcji dzielenia kolumn oraz grupowania wierszy, w obszarze Przekształć zakładki Narzędzia główne możemy znaleźć opcje Użyj pierwszego wiersza jako nagłówków (o niej pisaliśmy w pierwszym artykule na temat PowerQuery), Zamienianie wartości oraz Typ danych:
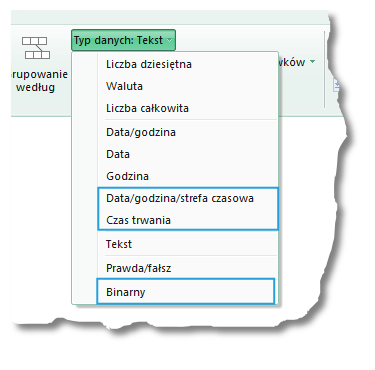
Oprócz standardowych typów danych dostępnych także w Excelu czy też w dodatku PowerPivot, mamy do dyspozycji 3 typy których nie spotkamy w innym miejscu: Typ daty z uwzględnieniem strefy czasowej, czas trwania oraz typ binarny.
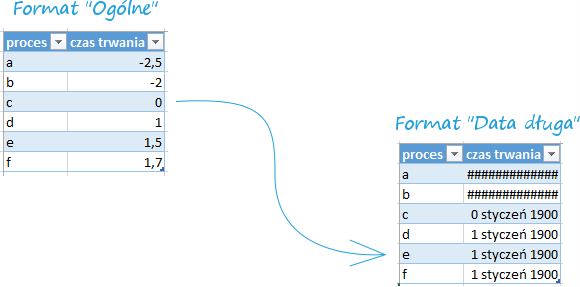
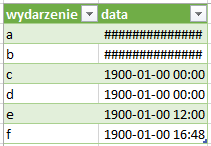
Format daty i godziny, podobnie jak w skoroszycie Excel, program rozumie format jako ilość dni od określonej daty. W skoroszycie jest to liczba dni od 1 stycznia 1900 roku, a właściwie od… 0 stycznia 1900 roku – to nie pomyłka – oznacza to, iż jeżeli wpiszemy liczbę 3 i zmienimy format danych na datę, to pojawi się 3 stycznia 1900 roku, ale jeżeli wpiszemy 0 to otrzymamy datę 0 stycznia 1900 roku. Niestety nie ma możliwości zapisywania dat dawniejszych – w przypadku użycia licz ujemnych i zmiany formatowania na datę w komórce pojawia się ciąg znaków hash – #.
W przypadku gdy użyjemy liczby niecałkowitej – np. 3,5 – oprócz daty zmienimy także godzinę, bowiem program interpretuje część ułamkową jako część doby która zdążyła minąć – tak więc 3,5 oznacza 3 stycznia 1900 roku, godzinę 12.00
W Power Query wygląda to nieco inaczej. Po pierwsze, daty są liczone od dnia 30 grudnia 1899 roku. Dodatkowo, istnieje możliwość zapisu daty wcześniejszej – jest ona identyfikowana jako liczba ujemna.
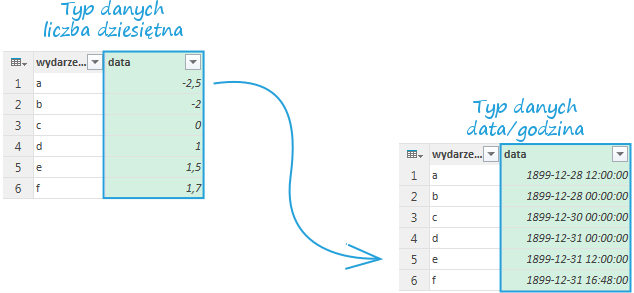
Niestety, załadowując takie daty do skoroszytu Excela znów otrzymujemy błąd w postaci komórki wypełnionej znakami hash:
Ponadto, w Power Query możemy wyświetlać możemy także oznaczenie strefy czasowej. W przypadku wybrania typu danych Data/godzina/strefa czasowa zostanie dodana informacja ile czasu jest dodanych/odjętych od czasu uniwersalnego (UT) na podstawie ustawień lokalnych. W przypadku Polski będzie to +01:00 bądź też +02:00 – w zależności od tego czy danego dnia obowiązywał czas letni, czy zimowy.
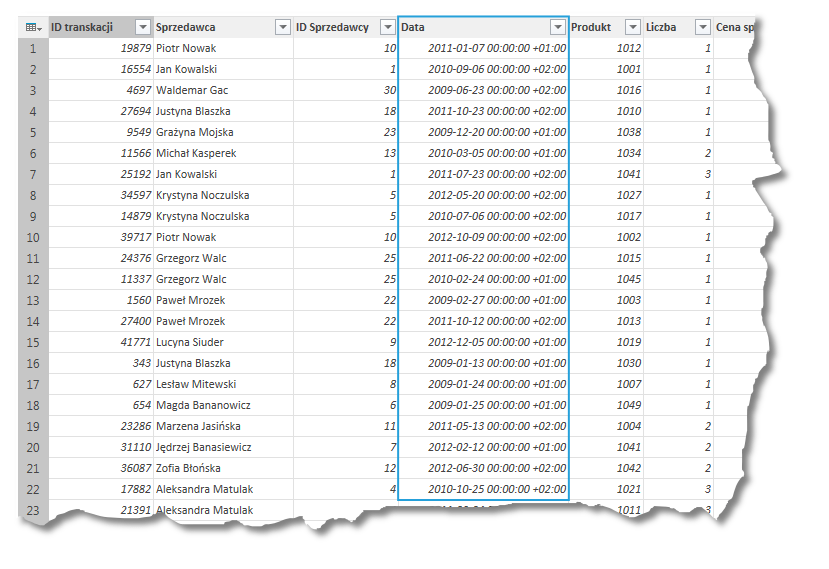
Operując na tak dawnych datach należy pamiętać o tym braku spójności pomiędzy PowerQuery a Excelem – w przeciwnym razie praca na takich danych i późniejsza próba ich eksportu do skoroszytu może kosztować nas wiele zmarnowanego czasu.
Typ danych Czas trwania to typ, w którym nie spotkamy się ani w skoroszycie, ani w PowerPivot – dostępny jest tylko w Power Query. Podobnie jak format daty, program konwertuje liczbę rzeczywistą na liczbę dni, godzin, minut i sekund. W przypadku konwersji liczby całkowitej otrzymujemy całkowita liczbę dni czas trwania (np. 2 to 2 dni czasu trwania). Aby oprócz dni skonkretyzować godziny, minuty i sekundy musimy posłużyć się liczbami rzeczywistymi które nie należą do zbioru liczb całkowitych – przykładowo pół dnia -12 godzin – to liczba 0,5, tak więc 2 dni i 12 godzin czasu trwania będzie oznaczone przez liczbę 2.5
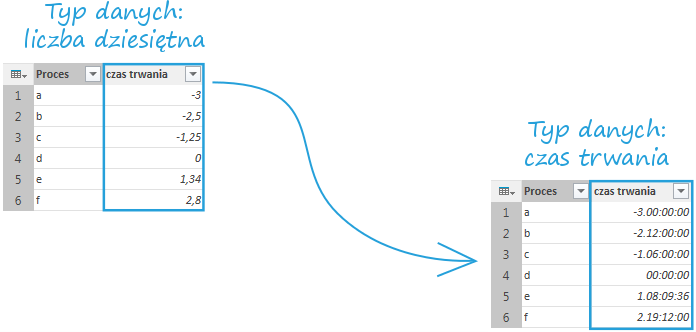
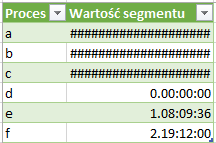
Mimo iż nie w skoroszytach Excela nie ma takiego formatu jak Czas trwania, to możemy załadować dane które będą wyglądały podobnie jak w Power Query – ich format danych zostanie określony jako niestandardowy. Nie mamy możliwości wczytania ujemnych wartości – podobnie jak w przypadku daty, zamiast tego otrzymamy komórkę wypełnioną znakami hash.
Dane binarne to między innymi obrazy czy też filmy. Możemy je zaimportować ze źródeł danych obsługujących ten typ danych (np. SQL Serwer) czy też zaimportować z określonego folderu. Takie dane możemy załadować do PowerPivot, a następnie do PowerView, gdzie możemy użyć obrazów w tabelach.
Zamiana wartości
W Power Query znajdziemy także tak klasyczną funkcję jak zamiana wartości, czyli odpowiednik opcji Znajdź i zamień (wywoływaną także skrótem CTRL + H) z wstążki Narzędzia główne skoroszytu Excela. Warto zwrócić uwagę, iż niestety nie mamy możliwości samego znalezienia interesującej nas wartości. Prawdopodobnie uznano, iż w tym dodatku taka funkcjonalność nie jest potrzebna – wszak dodatek ten służy raczej do importu danych, ich grupowego przetwarzania i wczytywania do skoroszytów, a zmiana pojedynczej wartości jest utrudniona, ponieważ dostępna tylko przez omawianą opcję zamiana wartości.
Trzeba zwrócić uwagę, iż wartości zamieniane są tylko w zaznaczonych kolumnach lub w zaznaczonej komórce – jeżeli chcemy, aby program zamienił wartości w całej tabeli, należy w pierwszej kolejności zaznaczyć wszystkie kolumny.
Wtórność?
Na podstawie powyższego omówienia metod przekształcania można by dojść do wniosku, iż Power Query nie oferuje nam zbyt wielu nowych możliwości w dziedzinie przekształcania danych. Wprowadza jednak możliwość działania na datach przed 1900 rokiem, a po za tym pozwala na wstępną obróbkę danych przed dodaniem ich do skoroszytu bądź też modelu danych. Dzięki temu możemy zmniejszyć wagę pliku oraz ograniczyć natłok danych (w przypadku, gdy dysponujemy zbyt dużą ich ilością) których bardziej dogłębną analizą możemy zająć się już korzystając z innych narzędzi.
Jakie jest Wasze zdanie na ten temat?



tutaj byl przyklad ze sprzedawca A sprzedal x, B sprzedal y itd. Jak jak na przyklad zrobic grupowanie, że A, B i C to 90% sprzedazy (powiedzmy ze wytyczna bedzie ilosc kg), a D,E,F,G,H lacznie to 10% sprzedazy. Przy czym to jest plynne bo w nastepnym miesiacu moze byc ze A,B, E to 90% sprzedazy a reszta to 10%.
dziekuje
Nie jestem pewien czy dobrze rozumiem pytanie, ale postaram się odpowiedzieć.
Można dodać kolumnę, gdzie sprzedawcom A, B i C nadamy jakieś oznaczenie (np. X), a pozostałym sprzedawcom inne (np. Y) i pogrupować ich według tych oznaczeń, a następnie w dowolny sposób przedstawić ich udział na rynku (np. zwykłym wykresem).
Czy Pana potrzebą byłoby automatyczne dzielenie sprzedawców na dwie grupy – jedną która przeprowadza 90% sprzedaży, a drugą która przeprowadza 10 %? To byłoby dosyć trudne do rozegrania, ponieważ taki warunek jest matematycznie niewystarczający aby określić jedno rozwiązanie. Przykładowo 90 % sprzedaży mogłoby być przeprowadzane zarówno przez trójkę A, B, C jak i A, B, D.